26.1. 信息可视化概述#

图 26.1 信息可视化。#
信息可视化(Information Visualization)是指将抽象的非空间数据通过图形化的方式呈现,以帮助用户理解和分析数据中蕴含的信息和规律。与科学可视化处理的物理场数据不同,信息可视化面对的数据通常是来自商业、金融、社会等领域的非结构化、半结构化数据,如文本、网络、层次结构等,不具有明确的空间坐标,维度较高,数据类型多样。因此,信息可视化的重点是设计合适的视觉映射和交互机制,有效组织和呈现信息,促进用户对数据的探索和理解。
26.1.1. 信息可视化的历史演进#
信息可视化的发展历史可以追溯到18世纪末,当时的统计学家和工程师开始使用图表来呈现数据规律,统计学与图形表达的结合成为关键突破。William Playfair 在1786年提出的折线图、柱状图和饼图,为后来的数据可视化奠定了基础。19世纪,随着数据收集的增多和科学研究的深化,可视化方法进一步发展,John Snow 在1854年通过霍乱病例地图揭示了水泵污染与疾病传播的关系,Charles Minard 在1869年绘制的拿破仑东征图通过二维图表同步展示军队规模、行军路线与温度变化,成为多维度数据可视化的经典案例。
19世纪末至20世纪初,数据可视化进入快速发展阶段。Florence Nightingale 设计“玫瑰图”优化医疗统计,政府机构广泛使用统计图表分析人口、犯罪与经济数据。 20世纪初,随着统计学的进步和心理学对人类认知能力的研究,信息可视化的设计开始关注数据呈现的有效性。John Tukey 在20世纪60年代提出了探索性数据分析(EDA)的理念,强调通过直观的图表来辅助数据模式的发现。数理统计理论的完善使可视化工具标准化,三维数据表达技术开始出现。此外,计算机技术的兴起也推动了数据可视化的发展,Ivan Sutherland 在1963年开发的 Sketchpad,被认为是交互式计算机图形学的奠基之作,交互式可视化强调通过图形界面让用户主动探索数据。
进入20世纪80-90年代,信息可视化逐步发展出完整的理论体系,并进入交互式可视化阶段。1983年,Edward Tufte 出版了《定量信息的视觉显示》(The Visual Display of Quantitative Information),强调数据表达的简洁性和有效性,奠定现代可视化理论基础。而 Stuart K. Card 等人在90年代提出的信息可视化参考模型,为信息可视化的流程提供了标准化框架。随着计算机性能的提升,可视化工具开始支持多维数据和层次结构数据的可视分析,如,Ben Shneiderman 提出的树图(Treemap)和动态查询(Dynamic Queries)方法,提升了用户对复杂信息的理解能力。
进入21世纪后,互联网和大数据技术的兴起,使得信息可视化逐步从静态图表发展为动态、交互式、甚至实时的数据探索工具,推动可视化进入全民应用阶段。交互式工具(如 Tableau、Power BI)支持用户自定义分析视角,动态图表(如可缩放时间轴、网络关系图)实现数据的深度探索。可视分析学(Visual Analytics)兴起,结合机器学习与实时数据处理,辅助金融、医疗等领域快速决策。增强现实(AR)与虚拟现实(VR)技术进一步扩展可视化场景,例如通过三维虚拟空间呈现城市交通流量或基因序列结构
信息可视化的发展从最初的静态统计图表,逐步演化为如今的多维、交互、实时甚至智能化的数据分析工具。它已经成为数据科学、商业分析、医学诊断、社会研究等多个领域不可或缺的手段,并随着技术的进步不断演变。
26.1.2. 信息可视化的核心挑战与未来趋势#
在大数据时代,随着数据规模的爆炸式增长和数据来源的复杂化,信息可视化也面临着来自数据处理难度加大、交互需求增加等多方面的挑战。
大规模与高维数据可视化:随着数据量的爆炸式增长(如社交网络数据、传感器数据、金融交易数据等),如何在保证性能的前提下有效可视化海量数据成为挑战。此外,高维数据(如文本、基因序列、物联网数据)难以在低维空间直观呈现,如何通过降维、投影等方法进行高效可视化是一个持续研究的问题。
多模式与多来源数据融合:现代信息系统通常涉及多种类型的数据,如结构化数据(表格、数据库)、非结构化数据(文本、图像、音频、视频)、时空数据(地理信息、轨迹数据)等。如何将这些异构数据进行有效整合和一致性可视化,提升数据的关联性和可解释性,是一个重要挑战。例如,如何将来自多个传感器的实时数据与历史数据进行融合并在一个统一的可视化界面中展示,这需要解决数据结构差异、语义冲突和动态更新等问题。
数据安全与隐私保护:随着数据的集中和共享,数据安全和隐私问题日益突出,尤其是医疗、金融领域,数据开放共享与敏感信息保护之间的矛盾凸显,需强化权限分级与加密传输机制。在可视化过程中,需要确保数据不被泄露、不被篡改,符合数据伦理和法律法规,同时又能满足用户对数据的分析需求。
可解释性与认知负担:信息可视化的目标是帮助用户理解数据,但复杂的可视化可能会增加认知负担,导致用户误解信息。因此,可视化方案需要从大规模和复杂的数据中筛选有效数据,进行直观简洁且符合用户心理模型的视觉设计,使用户能够快速、准确地理解数据,在降低认知成本的同时提高表达效率。
实时可视化与交互效率:许多应用(如金融分析、网络安全监控、智能交通系统)需要实时处理和可视化大规模数据流。大规模数据的渲染和交互会导致延迟,影响用户体验。大数据的快速更新要求可视化系统具备高效的图表绘制能力和快速构建能力。同时,系统需要具备良好的可扩展性,以应对不断增长的数据量和用户需求。如何在保证计算效率的同时,提供流畅的交互体验,使用户能够快速探索和分析数据,是一个重要挑战。
而当今的信息可视化领域,也正受到人工智能、多模态交互等计算机技术的深刻影响,正朝着更智能、更高效、更具解释性和交互性的方向发展,为数据分析和决策提供更强有力的支持。
基于人工智能的智能可视化:机器学习和深度学习技术正在用于自动生成可视化、优化布局、推荐最佳可视化方法。例如,基于强化学习的可视化系统可以根据用户的交互行为自适应调整可视化视图,提高数据分析效率。
多模态可视化:未来可视化系统将更加注重结合多种感官体验,如结合听觉(音频可视化)、触觉反馈(触摸交互)等,提升信息表达能力。例如,地震数据可视化可以结合声音来表示震动强度,从而提供更丰富的信息表达方式。我们将在§29.1一节展开介绍基于多种感官通道的智能交互方法。
解释性可视化与可视分析:未来的信息可视化将更加强调可解释性,结合因果推理、可视分析技术,使用户不仅能看到数据的表象,还能理解其背后的因果关系。可解释人工智能(XAI)领域的发展也进一步推动了可视分析的进步,帮助研究人员和工程师理解深度学习模型的决策过程。例如,在医疗数据可视化中,不仅要展示病人病情的趋势,还要提供潜在的病因分析。
大规模动态数据的高效可视化:针对流数据和高维数据的新型可视化方法将不断涌现,如基于 GPU 加速的实时可视化、大规模网络数据的增量布局算法等,以支持更高效的数据探索。
个性化与可视化推荐:未来的可视化工具将更加注重个性化,根据用户的背景知识、任务需求、交互偏好自动推荐最合适的可视化方案,使非专业用户也能高效利用可视化技术进行数据分析。
26.1.3. 信息可视化流程#
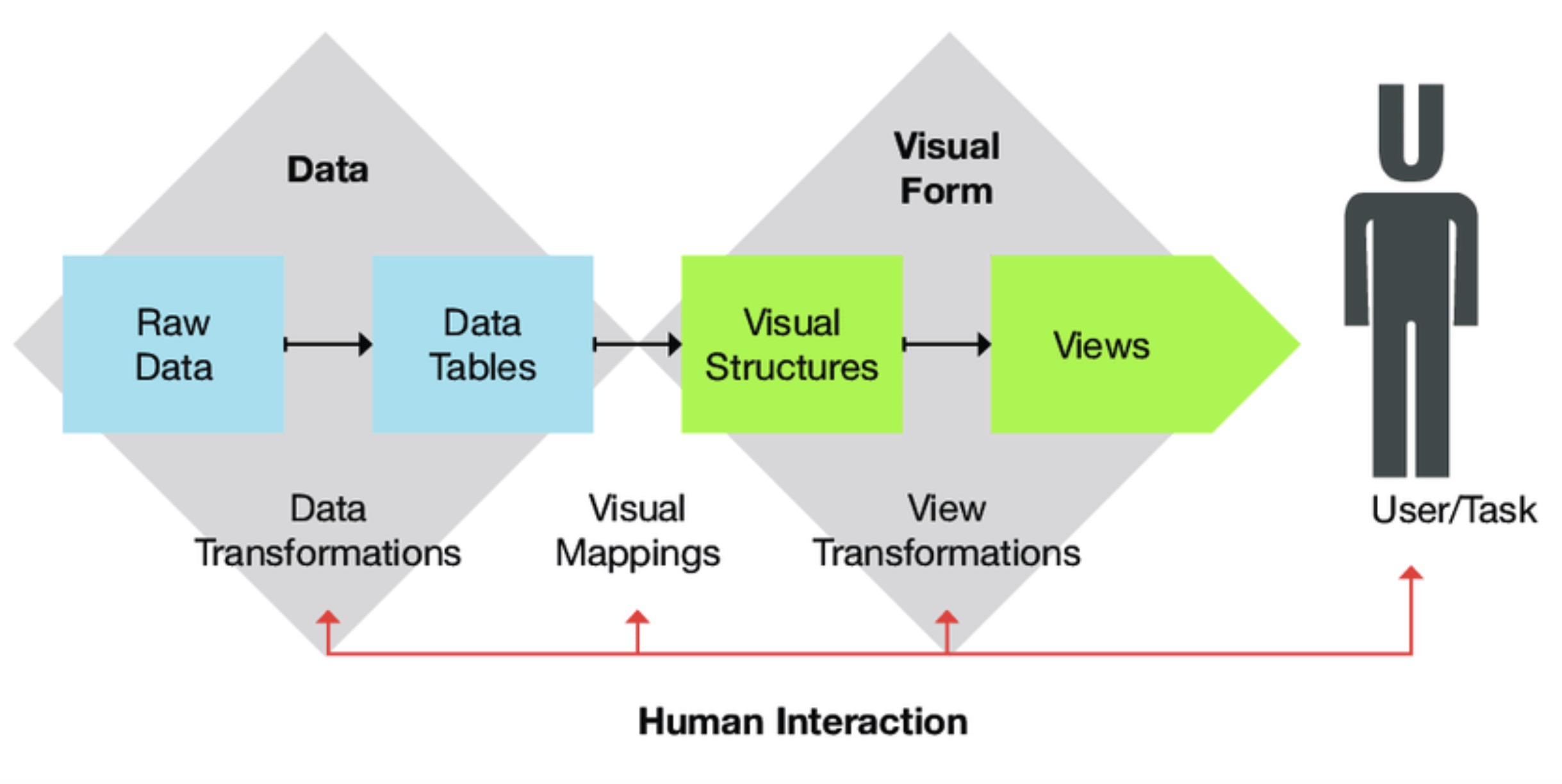
图 26.2 信息可视化的流程示意图。#
如图 26.2,信息可视化参考模型(Information Visualization Reference Model)[CMS99]展示了信息可视化的大致流程,将可视化过程分为以下几个阶段:
原始数据(Raw Data):可视化的起点,是未经处理的原始数据集,可能包括表格、文本、图像、时间序列等多种形式。
数据表(Data Tables):原始数据经过预处理和数据转换(Data Transformation),包括并不限于清理,过滤,格式化等,转换为适合可视化和分析的数据表形式。数据表通常由行(记录)和列(属性)组成,每个单元格存储具体的数值或类别。
可视化结构(Visual Structures):通过视觉映射(Visual Mapping),数据表被映射为可视化结构,即图形的视觉表现形式。这一阶段涉及:(1)视觉编码:将数据属性映射为视觉变量(如位置、颜色、大小、形状等);(2)布局设计:确定图形元素在空间中的排列方式(如节点链接图、矩阵图等)。
视图(Views):可视化结构最终呈现为用户看到的视图,并经过视角调整和用户交互等视图变换(View Transformation),来增强对视图中所蕴含信息的探索。
相比于科学可视化,信息可视化的一大特点是具有很强的互动性。信息可视化应用中,数据包含大量而丰富的信息,信息可视化的目标是寻找信息中潜藏的模式关系或特征,应用面向的用户是广泛而非专业的,因此用户需要参与到数据筛选、视觉表达选择、视图调整等各环节中,以此来获得用户满意的可视化结果。通过互动信息可视化,特别是在网站或应用程序中使用时,用户能够从不同的角度查看信息主题,并操作其可视化,直到达到所需的见解并满足广泛的用户需求和探索性体验。
26.1.4. 视觉映射#
在可视化流水线中,视觉映射是决定其表达效果的关键步骤。 视觉映射也被称为视觉编码(Visual Encoding),负责将数据从数据空间转化为可视化空间的视觉元素。这一过程通过视觉通道(Visual Channels) 实现,例如位置、颜色、大小、形状等,将数据属性映射为可感知的图形特征,从而帮助用户理解数据内在的模式与关系。
不同的视觉通道直接影响用户的认知效率。常见的视觉通道包括:
位置(Position):最有效的通道,适合表示定量数据(如折线图、散点图)。
颜色(Color):
色相(Hue):区分类别数据(如不同产品类别)。
亮度/饱和度(Brightness/Saturation):表示数值大小或强度(如热力图)。
大小(Size):表示数值差异(如气泡图)。
形状(Shape):区分定性数据(如不同节点类型)。
方向(Orientation):适合表示趋势或方向性数据(如箭头图)。
一般来说,定量类通道(如位置、长度、面积等)在人类的视觉感知上优先级高于定性类通道(如颜色、形状等) 根据 Cleverland 等人的研究[],人类对视觉通道的感知效率排序如下: 位置 > 长度 > 角度/斜率 > 面积 > 体积 > 颜色饱和度。 因此,在可视化设计中,应优先将关键数据维度映射到高感知效率的通道(例如用位置表示核心指标)。
在一张图表中,有时也需要使用多种视觉通道协同工作,从而编码更丰富的视觉信息。但需要注意的是,人类在同一时间内只能处理有限的视觉信息,当过多通道在同一空间内竞争用户的注意力时,视觉通道之间相互干扰会导致认知负荷增加:
当多个视觉通道同时使用时,某些通道可能干扰用户对数据的感知。例如,在散点图中,同时使用颜色和形状编码类别数据,可能导致用户难以区分类别(红色圆形 vs. 红色方形)。
当使用多个视觉通道传达同类的信息,也会导致资源浪费或视觉过载。例如,在饼状图中,同时使用颜色和标签标注类别,可能导致信息重复和图表拥挤。 因此,应使用恰当数量的视觉通道(通常不超过3-4个),尽量使用能协同工作的通道,并根据数据维度的重要性安排对应优先级的视觉通道。
在信息可视化流程中,针对不同的信息数据类型有着多样的视觉映射方法,这也是信息可视化的技术核心,接下来,本章将先介绍最基础的绘图技术,而后围绕不同类型的信息数据及其相关的可视化技术展开介绍。