27.1. 可视分析概述#
27.1.1. 可视分析的起源#
在大数据与可视化兴起之前,人们更多地依赖统计报表和传统的简单图表(如柱状图、折线图等)来理解数据。然而,随着数据规模爆炸与问题复杂度激增,仅靠简单图表或传统数据挖掘算法已不足以应对以下困境:
数据量过大:通过手动分析或常规图表已无法在短时间内读懂海量数据背后的模式。
数据维度多样:文本、图像、时序、多元关系……需要多角度、多步调地分析。
决策风险高:很多场合(如金融风控、医疗诊断)要求分析结果及时且有效。
同时研究者逐渐意识到:人类专家在模式识别、推理与创造性方面依然具有不可替代的优势,而计算机算法则在处理大量复杂计算时非常高效。 在此背景下,如何将人的洞察力与机器的计算力高效协同,成为学界和业界共同关注的焦点。可视分析正是顺应这一需求应运而生。
2004 年,美国国土安全部(The United States Department of Homeland Security,DHS)成立了国家可视化和分析中心(National Visualization and Analytics Center,NVAC),提出一个可视分析的研究计划,以应对日益增长的数据复杂性和分析需求 2005 年,可视分析的研究议程(Research Agenda for Visual Analytics)[TC05] 正式发布,标志着这一领域的正式确立。 该议程将可视分析定义为:”可视分析是一种分析推理科学,它通过交互式视觉界面,将人的灵活性、创造力和背景知识与计算机的存储和处理能力相结合,实现复杂、大规模数据集的高效处理和决策”。 由此便诞生了可视分析这一新兴领域,其目标是结合人类认知与高效算法,实现对复杂数据的可视化与深度分析。
27.1.2. 可视分析的理论、流程与技术#
27.1.2.1. 可视分析的基本理论#
人机协同:可视分析的最核心理念是“人在回路(Human in the Loop)”。它假设机器算法可以先对数据进行模式提取或自动推断,然后将结果通过可视化呈现给人;人则根据图表反馈进行思考、调整甚至修正算法参数,形成不断迭代的交互流程。
认知互动:在可视分析中,强调用户对可视图表的“认知参与”,希望人能够在图形中迅速识别出异常、聚类、分布趋势等,从而作出更好的决策或进一步探索。
杜米尼克·萨夏(Dominik Sacha)等人在2014年的工作 [SSS+14] 中提出了一种知识生成模型来解释可视分析中的人机交互与认知过程,如图 27.1 所示:
计算机部分(Computer):包含数据、可视化、算法模型,用于帮助分析者进行数据管理、挖掘与呈现;
人类部分(Human):强调分析者的推理过程,作者将其细分为探索(Exploration)、验证(Verification)和知识生成(Knowledge Generation)这三重循环;
回路式推理(Loops):
在“探索回路”中,分析者依靠可视交互操作(Action)来不断观察、尝试、寻找有意义的发现(Finding);
在“验证回路”中,分析者根据自己的洞察力(Insight)对已有假设(Hypothesis)进行证实或证伪;
在“知识生成回路”中,分析者逐渐将足够可信的洞察上升为新的知识(Knowledge),并且进一步影响后续的探索或验证。
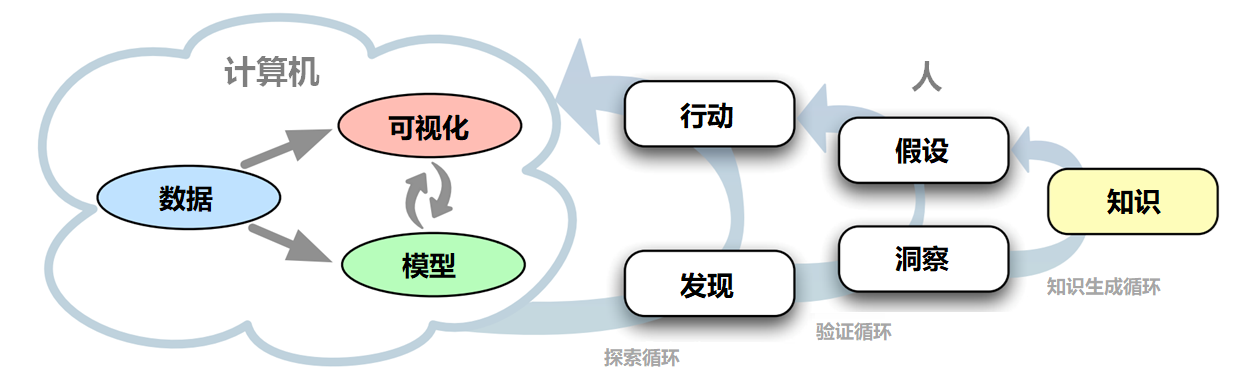
图 27.1 知识生成模型:首先定义领域任务,由计算机进行数据准备与自动分析,然后进行人机交互,通过图形反馈不断循环迭代,最终产生数据洞察,辅助决策 [SSS+14]。#
27.1.2.2. 可视分析的通用流程#
塔玛拉·蒙茨纳(Tamara Munzner)曾在2009年的工作 [Mun09] 提出了一个四层嵌套模型,旨在为可视化系统的设计与验证提供系统性指导,如图 27.2 所示:
问题域任务与数据特征化(Domain Problem & Data Characterization)
操作与数据抽象(Operation & Data Type Abstraction)
视觉编码与交互设计(Visual Encoding & Interaction Design)
算法设计(Algorithm Design)
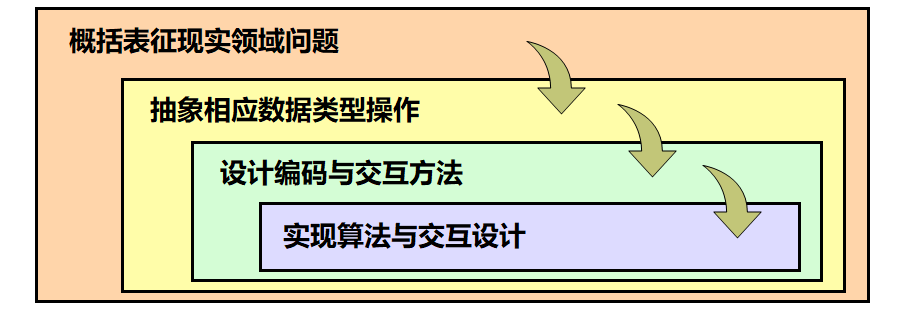
这一模型强调从领域需求,到抽象设计,再到视觉编码与算法实现的层层递进关系,为不同层次可能出现的“有效性威胁”提供各自对应的验证手段,从而指引研究者在设计系统时明确区分自己在每个层次上的贡献、假设和验证方式。
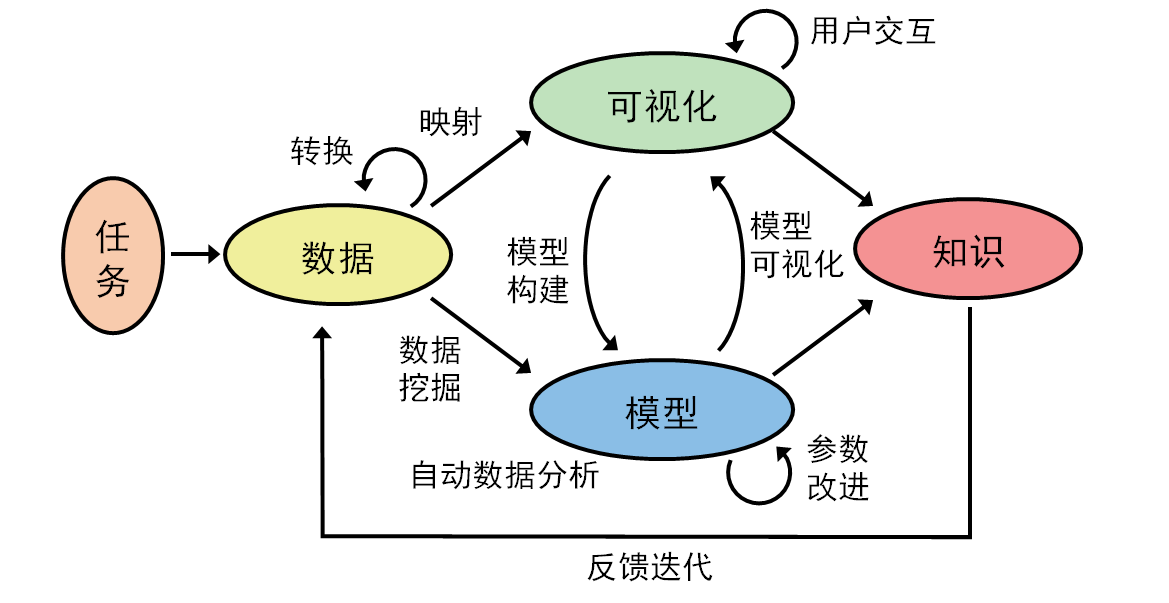
结合该嵌套模型,我们也可以更清晰地理解可视分析从数据到洞察的通用流程:在不断迭代的每个环节,既要关注特定领域的需求,又要做好数据的抽象与预处理,同时兼顾可视化编码、交互设计以及底层算法的效率。 因此,一个典型的可视分析流程应包括以下步骤:
需求分析与任务定义:明确可视分析要解决的问题,或要满足的需求是什么
数据准备:包括数据清洗、合并、多源融合,以及预处理(如降维或聚类等);
可视化编码与交互设计:基于数据属性选择图形编码方式(颜色、形状、位置等)呈现给用户;
模型与算法支持:用户根据任务需要,应用统计分析、机器学习、模式识别等算法或模型;
人机协同与迭代分析:根据用户对结果的反馈,不断试验假设,调整算法参数或方法并再次训练,记录推理与决策过程,迭代收敛;
知识发现与决策支持:在不断迭代中,用户逐渐形成对数据的深层理解,并为后续决策提供支持。
27.1.3. 可视分析面临的挑战#
虽然可视分析具有巨大的潜力,但在落地应用时依然面临诸多挑战:
1. 数据规模与实时性能: 体量庞大的数据(甚至是实时流数据)会带来存储、传输与渲染等多方面压力; 需要高效的可视化算法与大规模计算框架支撑,才能在交互操作时保持流畅。
2. 多维度与高复杂度: 很多数据集含数百甚至上千维度,如何在有限的图形空间中有效展示并让用户理解; 需要多种降维、聚合和可视编码技术相结合,并且设计多视图协同方案。
3. 算法解释性与可信度: 机器学习模型(尤其深度学习)常被视为“黑箱”,结果不透明; 可视分析需要给用户提供模型解释或可视证据,帮助他们信赖且理解输出结果。
4. 跨团队与跨学科合作: 可视分析往往需组合数据科学家、领域专家、可视化研发工程师等多角色; 协同工作和知识共享方面的工具与流程仍需进一步完善。
可视分析与传统的信息可视化有许多相通之处,但也有一些本质区别。 相通之处在于,两者都利用人眼的高带宽通道优势,将抽象数据以直观的视觉形式呈现,放大人的认知能力。但信息可视化更侧重表示,即如何准确、高效、美观地将数据映射到视觉通道;而可视分析则更侧重分析,即如何与用户进行有效互动,共同完成数据推理和决策任务。信息可视化强调”以用户为中心”,可视分析则强调”以任务为中心”。此外,信息可视化关注”可视化”,可视分析则关注”可视化+分析”,因而对分析模型、交互机制、认知理论等有更高要求。从这个角度看,可视分析是信息可视化在大数据时代的自然延伸和必然选择。