29.1. 三维交互技术#
相比于传统的二维交互,进行三维空间中的交互要困难得多,主要原因包括:
物体自由度高:相较于二维对象,三维空间中的对象具有六个自由度,包括三个空间坐标(X,Y,Z)和三个旋转轴(滚转、俯仰、偏航),这增加了操控的复杂性。
视角遮蔽严重:操作大量三维对象时,不恰当的摄像机角度可能导致物体直接互相重叠、遮挡,使得用户难以准确地定位和操作对象。
操作思维局限:目前人们所习惯使用的交互工具(如鼠标、显示屏)几乎完全是基于二维的,人们并没有关于三维空间操作和编辑的共识,需要通过三维交互技术的发展来塑造对三维交互的理解。
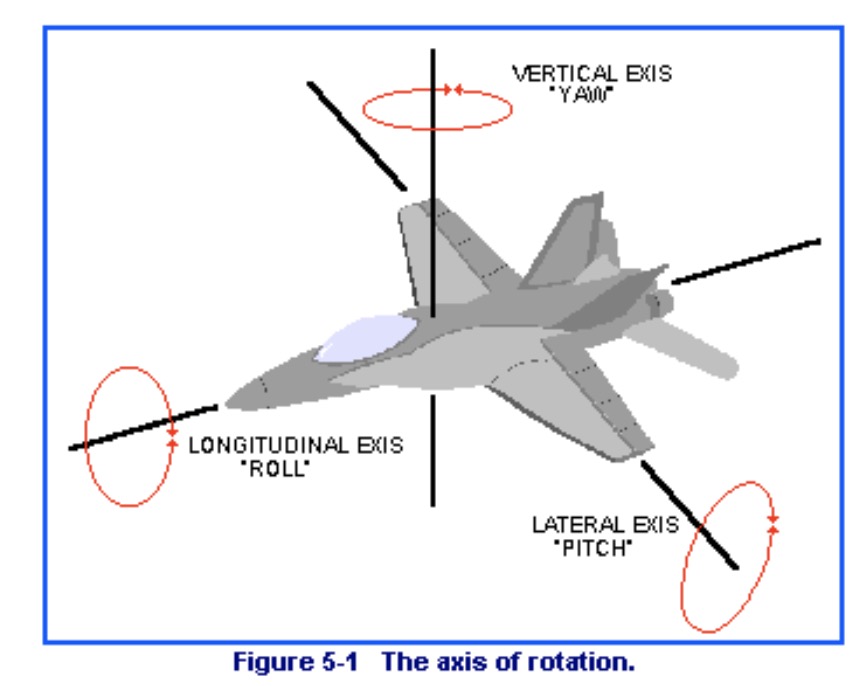
图 29.2 三维飞机模型的三个旋转自由度:滚转(roll)、俯仰(pitch)、偏航(yaw)。© Wikipedia#

图 29.3 三维场景包含复杂的遮挡关系和空间层次结构。© Wikipedia#
因此,三维交互技术不仅需要考虑到操作的直观性,还要解决视角、空间理解和操作工具的局限性,这些都使得三维交互设计与实现更为困难:
三维选择:点击设备不再是在二维屏幕上进行选择,而是在一个具有纵深的三维空间中进行选择,三维场景具有复杂的层次结构和遮挡关系,这给准确选中目标物体造成了困难。
窗口部件:作为展示信息的窗口部件一般以二维画布的形式存在,如何在三维空间中进行窗口布局、是否需要加入阴影或遮挡关系等问题需要精心设计。
运算速度:三维场景中的计算量显著高于二维场景,需要以高效的计算来维持人机交互的实时性。
为了解决这些困难、获得更自然的交互体验,人们不断探索着三维交互的技术范式。 最基础的三维交互手段借助于各类经典交互设备,如显示屏、鼠标键盘等,通过传统方法操作二维屏幕内的三维对象;接着,人们也通过三维空间定位技术建立起了更直接的从三维物理世界到二维数字世界的空间映射,突破了传统鼠标键盘等输入方式的限制,允许用户通过物理世界中的操作与数字空间直接进行交互;而后,人们尝试超越二维屏幕的三维交互,头戴式显示、体积显示等三维显示技术使之成为了可能,三维显示为用户提供了绝佳的沉浸式视觉体验,于是基于多通道交互的智慧交互方式随之兴起,三维显示与多通道交互的深度融合带来了更真实高效的三维交互方式。 本章将从三个阶段依次探讨“自然和谐的人机交互”的发展进程。
29.1.1. 基于经典交互技术的三维交互#
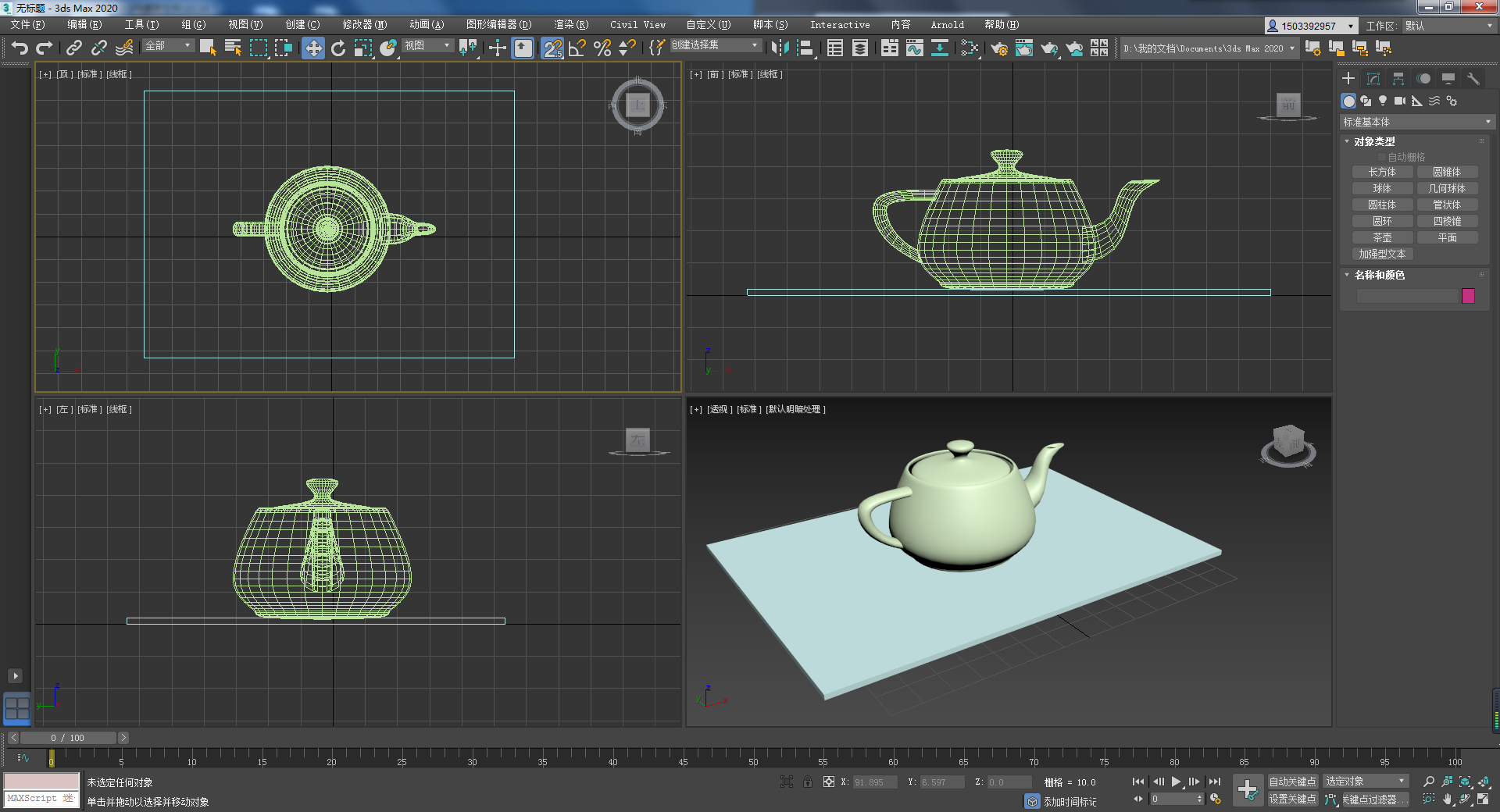
图 29.4 3D Max中的三视图 © From zhuanlan.zhihu.com#
经典交互技术依赖于二维屏幕进行显示,基于这类技术的三维交互在二维屏幕内操作三维对象,其主要挑战在于如何将二维的输入输出同三维空间建立联系。一种经典的方法是基于多视图,如图 29.4所示,常见于各种三维建模软件。这一类方法往往建立四个视图窗口,由三维对象的三视图和一个来自用户控制的自由视角主视图组成。当用户需要对物体进行三维变换时,主视图可以进行六自由度的三维变换,而三视图的每个视角可以进行相应视角下的四自由度二维变换,这有效地缓解了视角遮蔽和三维变换自由度高的问题。
另一类方法 [SHR+92] 则将二维中的控制杆(handle)扩展到三维,如图 29.5 所示,于是用户可以通过点选特定轴完成移动、伸缩、旋转等操作。这一类方法往往不依赖多角度视图,将三维操作转化成二维操作,提供了更加简单而自然的交互方式。

图 29.5 3D控制杆 [SHR+92] :左图所示的标准长方体上具有一系列可交互的三维控制杆,右图展示了缩短蓝色控制杆后因此变形的三维物体。#
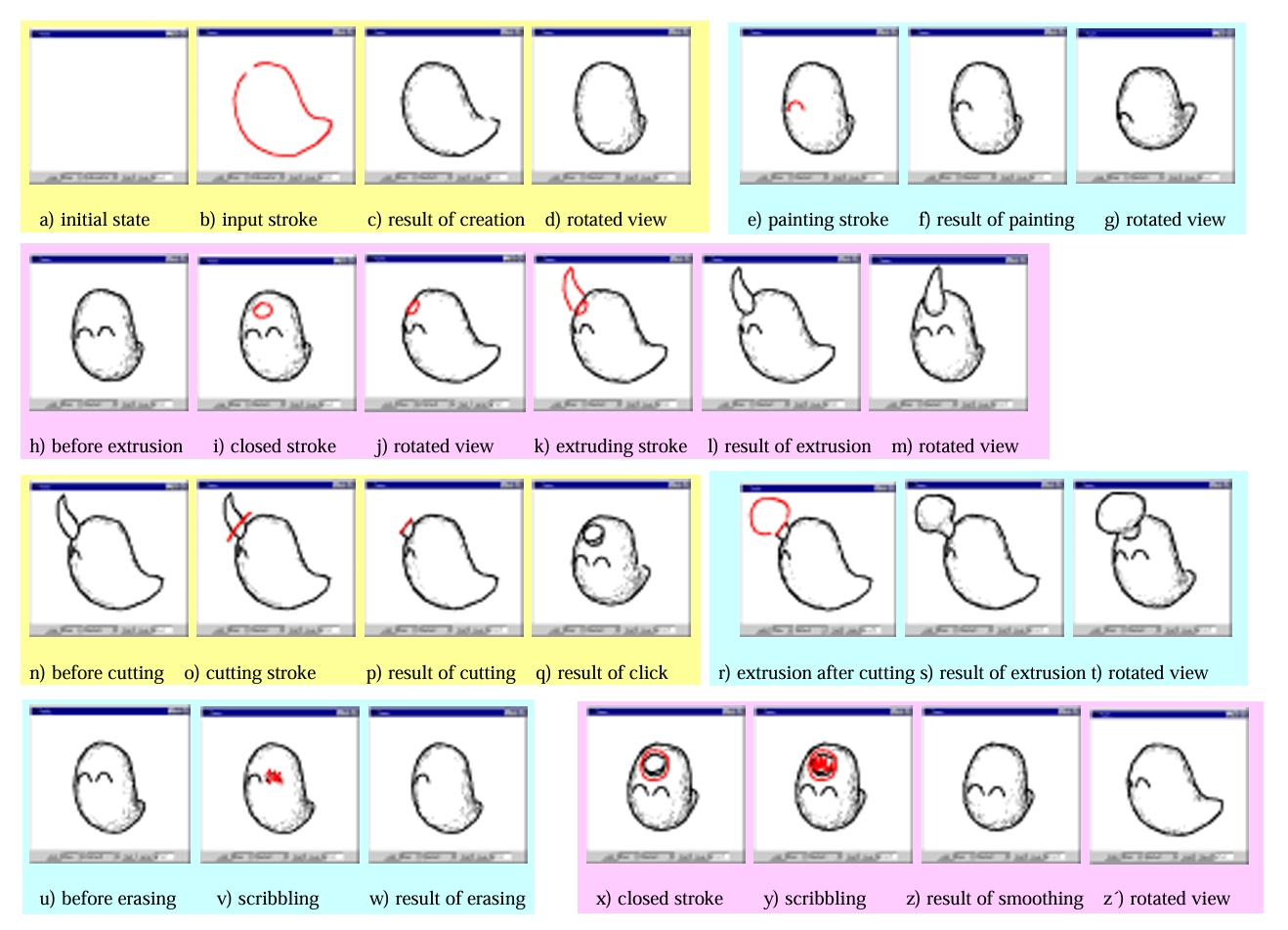
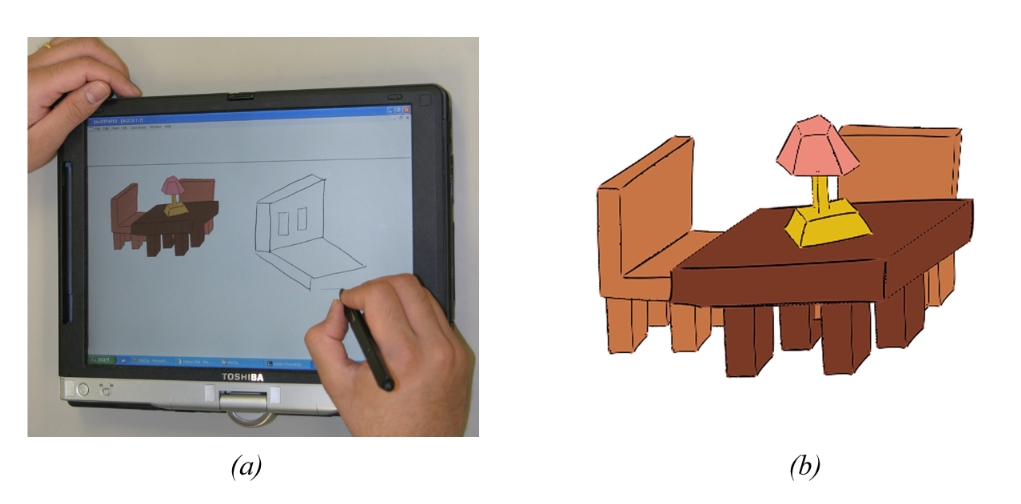
除了上述鼠标操作的经典方法外,也有一些方法允许用户使用触控笔草绘来进行三维交互,如图 29.6 [IMT99] 和图 29.7 [SC04],用户可以通过在平板上勾画物体的外轮廓来构建出三维物体,并且可以通过笔划对物体进行切割或拼接等操作。
29.1.2. 基于三维空间定位设备的三维交互#
基于经典交互技术的三维交互开启了人们对于三维交互的思考与认知,但从二维获取的输入终究是受限的,为了获得更准确、自然的三维交互,人们开发出了全新的三维交互设备,为进行三维交互提供了更直接的空间映射和更自然的交互体验,如三维空间定位设备、各类传感器、可穿戴设施等,于是人们得以综合图形界面和物理传感,迈入了“普适计算”(Ubiquitous Computing)时代。
29.1.2.1. 三维空间定位设备#
要建立从三维空间到数字空间的直接映射、通过三维空间的移动来传达输入信息,那么首先要获知输入设备或用户在三维空间中的信息。三维空间定位设备的发展为促进三维交互技术的发展提供了重要基础。
早期的三维空间定位设备包括空间跟踪定位器(或三维空间传感器)和数据手套(data glove)。
空间跟踪定位器(或三维空间传感器)是指一类定位于身体或虚拟现实交互道具上的设备,往往是一个小型的芯片,能够感知空间六自由度(位置与旋转)及其变化并跟踪运动。空间跟踪定位存在低频磁场式和超声式传感器等不同类型,采用磁场或超声来计算设备在三维空间中的运动状态。我们将在下一节里详细讲述如何利用空间定位设备来定位用户的位姿。
数据手套则是一种穿戴设备,通过其上的传感器可以精确的捕捉手指和手腕的相对运动,获取各种手势信号,并且可以配合一个六自由度的跟踪器,跟踪手的实际位置和方向。
29.1.2.2. 触觉和力反馈器#
触觉和力反馈器是一类模拟现实世界中触感和反作用力的设备,包括力学反馈手套、力学反馈操纵杆、力学反馈笔、力学反馈表面等装置。这一类设备希望使用户感觉到仿佛真的摸到了物体,主要通过视觉、气压感、振动触觉、电子触觉和神经肌肉模拟等方法实现。其中,电子触觉反馈器是向皮肤反馈宽度和频率可变的电脉冲,而神经肌肉模拟反馈是直接刺激皮层,这些方法都很不安全;较安全的方法是气压式和振动触感式的反馈器。然而,人的触觉非常敏感,精度一般的装置无法满足要求;对于触觉和力反馈器,还要考虑到模拟力的真实性、施加到人手上是否安全以及装置是否便于携带并让用户感到舒适等问题。由于精度、真实感、安全性等上述问题,目前这一类设备尚缺乏成熟产品。


图 29.8 左:数据手套;右:触觉反馈套装。 © Haptx#
29.1.2.3. 实体用户界面(Tangible User Interface, TUI)#
实体用户界面是一种用户通过物理环境与数字信息互动的界面,最初称做可抓取用户界面(Graspable User Interface), 通过让用户操控实际的物理物体来与计算机系统进行交互。这些物体可以是可触摸、抓取、转动、滑动或移动的对象。用户通过与这些物体的互动,传递指令给计算机,而计算机则根据物体的位置、形状、动作等参数作出响应。 实体用户界面的先驱是在麻省理工学院 Media Lab 带领实体媒体小组(Tangible Media Group)的石井裕(Hiroshi Ishii)教授,他获得了 Chi’2019 终身成就奖。他和布莱格·乌尔默(Brygg Ullmer)在 1997 年提出了对实体UI的愿景 [IU97],称为可触比特(Tangible Bits),旨在给数字信息赋予物理形态,使比特直接可操控和感知,追求物理对象与虚拟数据之间的无缝结合,他们据此对 TUI 的设计提出以下准则:
物理表现与底层数字信息在计算上耦合:当用户移动或旋转带有传感器的物体时,系统会实时检测物体的运动,并在虚拟界面中做出响应。这两者(物理世界和数字世界)相互影响和协调,彼此“沟通”。
物理表现体现了交互控制的机制:物理对象是用来与计算机互动的控制工具。例如,通过触摸、旋转或移动一个物体,用户能直接控制计算机中的某个程序或虚拟对象。
物理表现在感知上与数字表现耦合:物理物体的变化不仅通过触觉反馈给用户感知,还通过视觉和听觉等感官反馈来传递数字世界的信息,从而使用户能同时感知物体和数字世界之间的关系。
实体的物理状态体现系统数字状态的关键方面:物理物体的变化反映了计算机系统中虚拟状态的变化,物理物体的位置、旋转角度等也会与虚拟物体的状态一一对应,使得两者保持一致。
石井裕教授也将实体交互界面应用在城市规划 [UI99] 中,如设计了基于建筑物物理模型的桌面工作台,提供了对气流、光照、人流、建筑材料设置等城市规划功能的观察和规划手段。 在 2012 年,他发表了关于实体用户界面的综述论文 [ILBL12],提出实体用户界面设计的新范式:“实体设计需要在物理世界的不同材料和形态中精心设计界面,寻求不同属性的融合。”在这种设想下,未来将有“革命性原子”(Radical Atoms)材料,如同数字世界中构成数据流的比特一样,它将作为物理-数字世界交互的材料单元,提供不同属性的真实物理材料到数字空间的对应,于是人们可以通过对物理世界实体施加各种操作,这些操作均能对应到数字世界中,使物理-数字世界共同演化。如图 29.10 展示了直接操作实体界面来制作一个正红色外壳的过程,人类可用类似捏黏土的方式来进行数字建模。

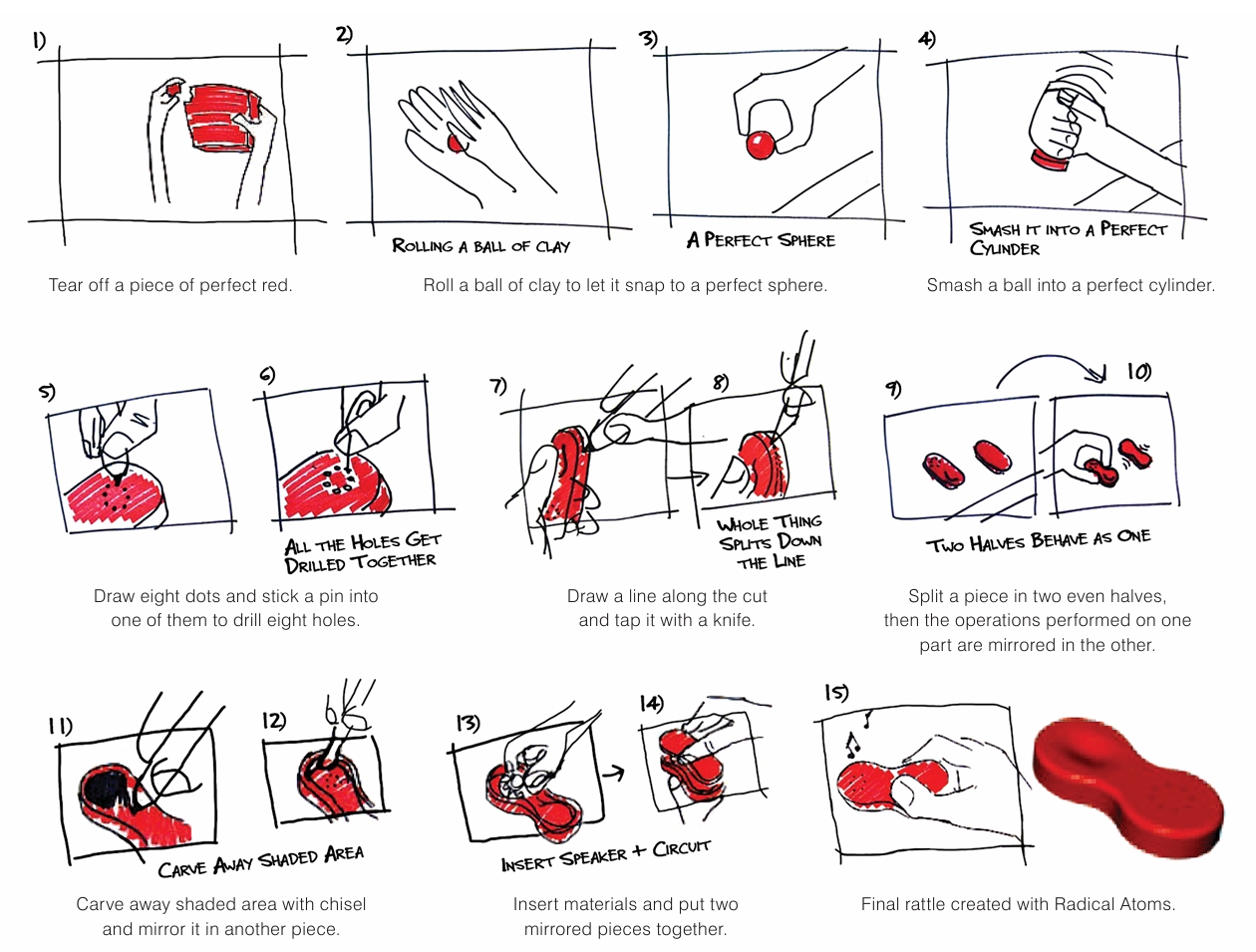
实体用户界面的另一个典型例子可以参见凯伦·范德洛克(Karen Vanderloock)提出的 Skweezee 系统 [VVASG13],他们通过在实体设备上定义了标准的交互操作来使得用户可以通过直接的物理实体实现交互控制。图 29.11展示了 Skweezee 中一种设备(cuboid)的七种标准交互操作。

29.1.2.4. 物理控件(Physical Widgets)#
实体用户界面的发展有赖于物理控件(Physical Widgets 或 Phidgets)的发展,一类具有物理实体的可重复使用的交互设备。与 Skweezee 系统这样的 TUI 技术不同的是,物理控件往往是固定在桌面的交互设备,例如各种压力、温度的传感器控件或相机,其输入输出并配备有物理实体,允许用户通过物理交互来传递控制信号。如图 29.12 所示的桌面交互,利用相机摄影将用户的动作实时传递给系统并据此在桌面显示屏中作出交互反馈。物理控件的设置初衷在于提供一种便捷、低成本的方式来让计算机能够方便地获得与现实世界进行物理交互的能力。物理控件往往统一为USB接口,使用时只需要连接到计算机设备上,随后通过特定的驱动程序来处理数字输入输出。

与3D打印技术结合使得物理控件的制作成为可编程的,Vázquez等人利用3D打印技术设计了一种气动装置 [VazquezBD+15],如图 29.13所示,通过按钮、滑动条、旋钮等各类空气元件的内部压力改变来获得对应的驱动力和输入信号,在配备电子元件后,还可以将物理量信息转化为电信号来实现定量的输入控制。

图 29.13 3D打印制作出的气压传感控件。[VazquezBD+15]#
29.1.3. 基于三维显示与多通道交互的智慧交互#
三维显示技术的发展进一步推动了三维交互技术的革新。在三维显示技术营造的沉浸式视觉环境中,为了获得更加沉浸的交互体验,人们力图通过更自然的表意手段进行交互,包括并不限于姿势识别、手势识别、视线追踪、语音识别、面部表情识别、人体动作识别等。当然,这些多通道交互方式并不仅限于AR/VR等使用三维显示的应用中,它同样可以用于使用二维显示(如经典的屏幕显示)或无显示(如智能家居或自动驾驶)的场景,其中,与二维/三维用户界面相结合的多通道交互也被称为多通道用户界面交互。本小节中我们将主要介绍三种主要的多通道交互手段。
29.1.3.1. 手势识别#
“手势”(gesture)是人类利用手掌和手指的运动和位形构建的一套表意系统,如图 29.14所示,需要注意的是,在“手势识别”这一语言环境中,“手势”关心的是手掌或手指等输入工具的移动路径,而不仅是开始、结束时刻的位置。因此“拖拽”并不被认为是一个手势,因为它的操作结果只与起始点和结束点有关。另外我们强调手势与位姿的不同:位姿关心的是某一时刻的静止状态,而手势关心的是空间路径。为了获取路径,手势识别技术需要设计路径的表达方式(或者说是路径曲线的插值方式),从而令程序能够识别出不同的手势并获取对应的输入信息。如何更加精确地、高效地设计路径表示方式并识别路径,是手势识别技术的一大核心问题。获取手势的方式是多样的,既可以使用单个手指完成手势,也可以使用多个手指共同组成手势;可以通过计算机视觉技术从相机录影中获取手势,也可以通过Kinect或Leap Motion这类实时传感设备识别手势,或通过数据手套等穿戴式设备来获得手部姿势和位置。
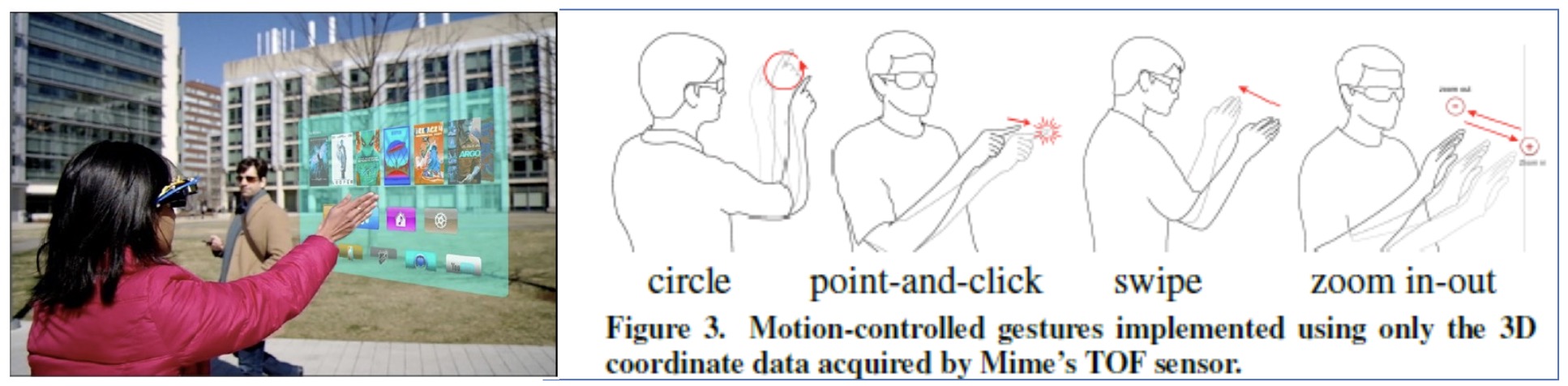
图 29.14 利用内置于眼镜中的传感器识别手势并进行交互。#
事实上,通过鼠标、触控笔、手指在屏幕上的路径类操作也被认为是手势,如图 29.15所示的用于文本校阅[Col69, RW86]和图形编辑[BFH+83]中的手势。这类手势被广泛用于智能触屏设备以及ProCreate、OneNote等APP中,如翻页、回到主页面等常用操作通常被设计为一些简单易学的手势以提供快捷友好的交互手段。
 用于文本校阅中的手势设置。
用于文本校阅中的手势设置。
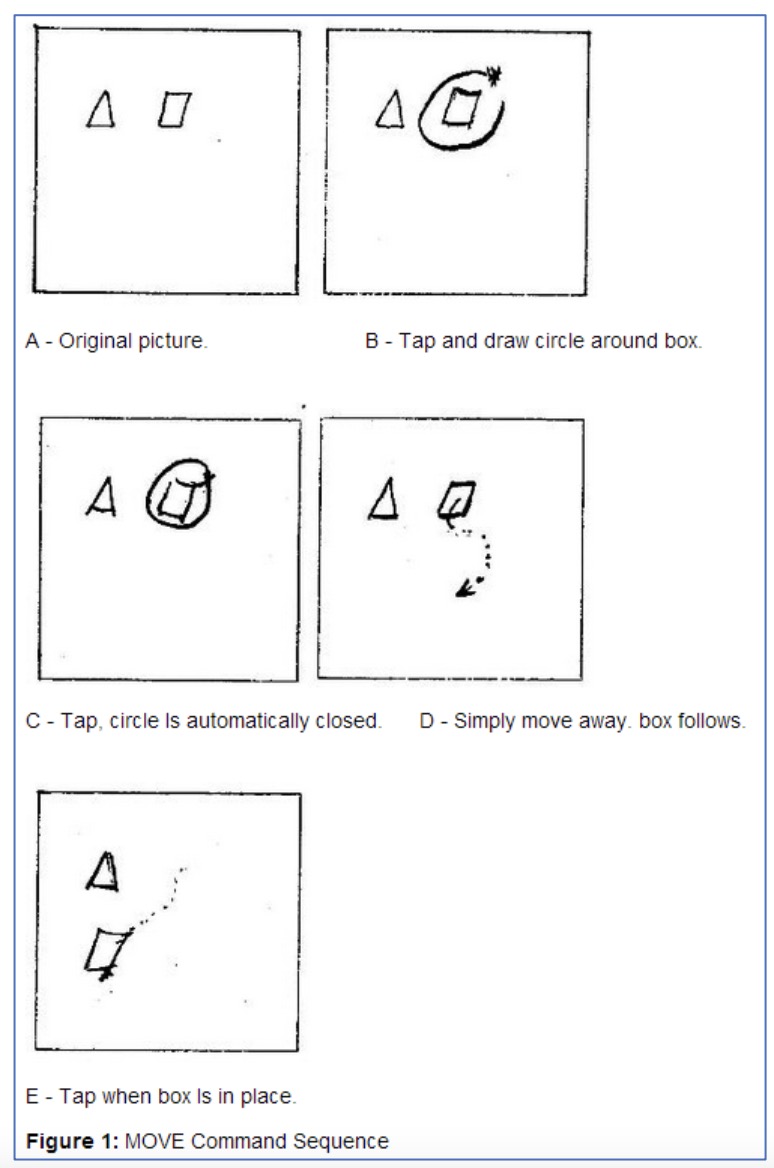 用于图形编辑中的手势操作。
用于图形编辑中的手势操作。
图 29.15 文本或图形操作中的手势。#
基于手势的交互的最明显优势是直接而快捷,便于用户理解和使用。相比于基于鼠标等点击设备先选中再操作的流程而言,单个手势可以同时表达对操作对象的选择和操作意图(如:”对某个物体打叉“,该步骤既选中了操作对象,也指明了操作内容),因此提高了信息传递的效率,使得交互过程更加高效。另外,由于手势的种类众多,因此潜在的设计空间很大,在人们已经建立了对一些手势的常识先验(如手语)的情况下,手势将成为一种十分自然的交互手段。基于手势识别的交互也能很容易地集成到事件驱动的编程中。
而另一方面,基于手势识别的交互也有诸多劣势。首先,除去一些约定俗成的手势,如果程序设计了新的手势操作,那么如何让用户迅速掌握手势用法、提高交互设计的可见性将是一个难点。其次,手势交互模式难以告知用户处理过程的中间信息(如:鼠标点击后若程序正在处理,会将鼠标图标变成旋转中的圆圈来表示”加载中“,但手本身并非虚拟元素因此无法直接对它做更改),于是用户将难以获知自己的交互操作是否被接收并处理。另外,为了尽可能满足所有用户的需求,手势设计需要考虑到残障人士在完成手势中可能存在的操作困难。手势操作一般来说慢于键盘,因此为了高效地传递较为复杂的信息,手势交互仍需要与其他交互方式相结合使用。最后,用户输入的手势会有旋转和放缩上的差异,如图 29.16所示,对识别结果造成影响,而不同手势类型对旋转不变性和放缩不变性的要求不完全一致,因此需要开发者的精心设计。

图 29.16 具有不同旋转或不同大小的手势输入有可能对应同一个手势,也有可能对应不同手势,需要手势识别程序进行甄别。#
主要的手势识别技术包括:
模式匹配技术:是一种最简单的识别技术,将传感器输入的原始数据与预先存储的模板进行匹配,通过度量两者之间的相似度完成识别任务。该类技术从输入数据中提取出有效特征,如曲率、速度、方向及其变化等,并使用支持向量机(Support Vector Machine, SVM)等分类算法进行识别。这类方法算法复杂度较低且不需要大量训练数据,适用于手势种类有限且差异较大的场景,常被用于早期的触摸屏设备中简单的手势输入。
神经网络技术:神经网络方法从数据集中自行学习手势特征,避免了手动设计特征的麻烦,可以处理更复杂多样的手势。神经网络具有的自组织和自学习能力和分布性特点,使该类技术抗噪声能力比较强,能处理不完整的模式,也能拓展应用于新的场景和人物。该类技术被广泛应用于自动驾驶、虚拟现实等应用和产品中。
统计分析技术:使用统计模型分析是手势数据的特征向量,是一种基于概率的分类方法,采用贝叶斯极大似然估计(Maximum Likelihood Estimation, MLE)确定分类函数,也可以采用隐马尔可夫模型(Hidden Markov Model, HMM)处理时序手势数据。该类方法有较好的抗噪能力,能相对稳健地处理或预测手势。
29.1.3.2. 眼动追踪#
当用户在浏览信息时,会自然地将目光聚焦在感兴趣的内容上,如图 29.17、图 29.18所示,因此,视线可以被看成一种新型的点击设备,交互程序通过“自动”将光标置于用户的视线所在实现人机交互。

图 29.17 阅读文本时典型的眼动过程。注视主要停留于有实际表意的单词的中部,并会逐行扫描过文件。#
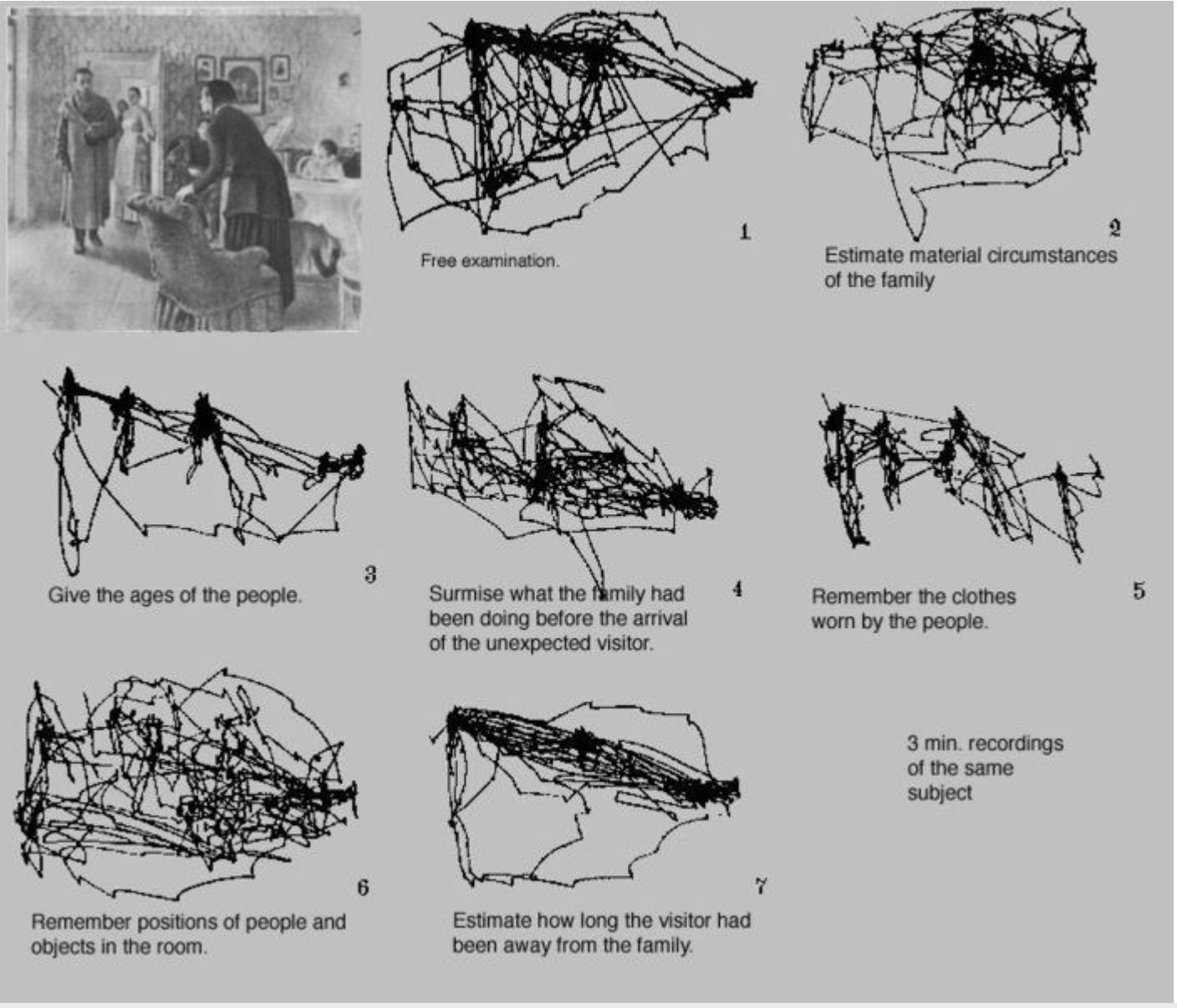
图 29.18 阅读图片时的眼动特征。给出左上角的图片,在无提示时注视主要集中在人脸,但整体上是杂乱的。在给出提示(如年龄、衣着、环境、位置)后注视会相应地集中到提示对应的信息的部分。#
典型的眼动包括:
跳动(Saccades)是眼球从一个注视点快速移动到另一个注视点的动作,通常持续时间较短(几十毫秒)。跳动是眼球快速扫视过程中的大部分眼动,通常用于切换注视的焦点。
注视(Fixations)是指眼睛的中央窝对准某一位置停留不动的状态,通常持续几百毫秒到几秒钟。在注视期间,眼球的运动非常微小(一般不会超过1° 视角),反映了对某个物体或区域的集中关注。
平滑尾随跟踪(Smooth Pursuit)是眼睛在注视一个缓慢移动的物体时,平滑而连续地跟随其运动的过程。 眼动追踪交互主要利用的是眼球的跳动和注视。
眼动追踪交互技术的相关研究主要涉及两方面:一是视线跟踪原理和技术,用于准确捕捉用户的视线所在;二是人机界面的设计和技术,用于确定眼动模式所具体对应的交互模式。其中,前者是该类交互技术的核心难点,接下来我们将对其进行简要介绍。
视线跟踪技术的发展大致经历了三个阶段。
早期尝试会使用直接观察的方法,或是将一个橡胶吸盘吸在眼球表面,连续拍照记录数据,这种方法非常的不方便、不舒适。眼电法(Electrooculography,EOG)通过记录眼周若干点位的电信号变化来测量眼动轨迹的过程,但仍然是一种不准确的方法。
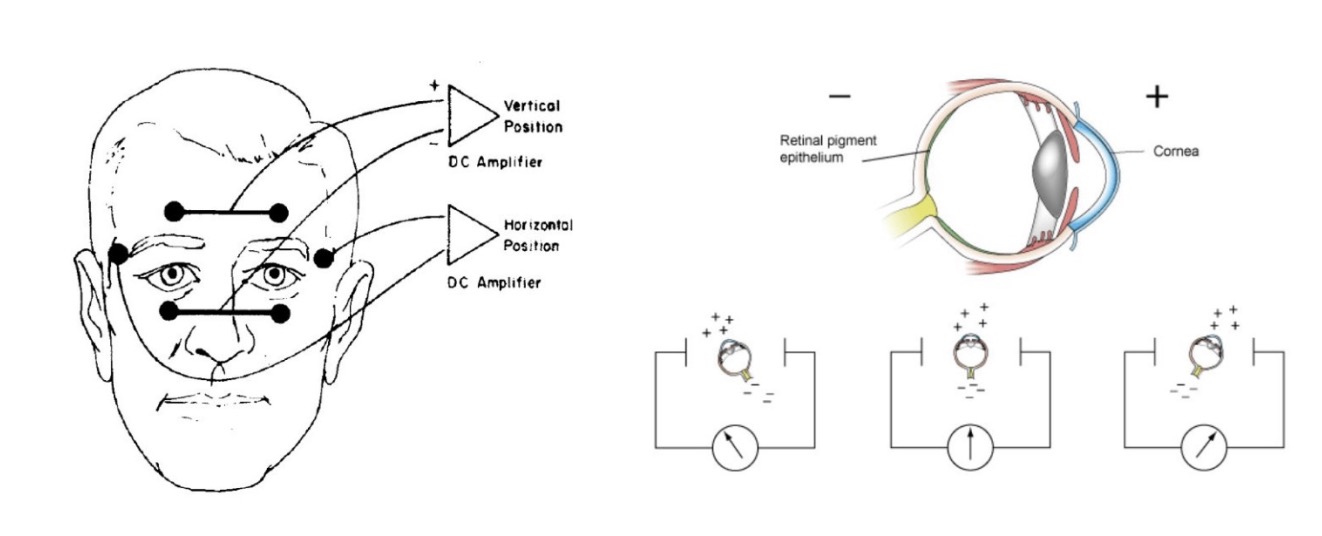
图 29.19 利用眼电法记录眼动信息。#
为了获得更准确的眼动信息,有研究将电磁巩膜搜索线圈嵌入到专用的隐形眼镜中,并将线圈连接到记录设备中,通过眼睛运动产生的感应电压来记录眼动轨迹。实验会令研究者位于法拉第笼中以屏蔽外部电磁干扰,并固定头部以减少头部动作的干扰。但这种方法对眼动实验参与者的眼睛有较大的影响,长时间实验会造成一定的生理伤害。

图 29.20 利用红外边缘反射与搜索线圈追踪眼动。#
目前最常用的眼动追踪技术是基于视频的眼动追踪,其基本原理是使用相机摄取受试者的眼睛图像,而后利用数据分析处理技术实时计算出眼珠的水平和垂直运动的时间、位移距离、速度及瞳孔直径、注视位置等信息。 设备捕捉到的眼动数据通常是嘈杂的,因此对眼动数据的预处理是必要的,其目的是滤除噪声、识别定位及局部校准与补偿等,稳定提取眼睛定位坐标。另外,眼球存在固有的抖动,眼睛眨动、头部剧烈移动会造成的数据中断,这些干扰信号使得提取有意义的眼动信息非常困难。因此解决此问题的办法之一是利用眼动的某种先验模型加以弥补。
在面向广泛用户群体的低成本应用场景中,通过结合普通摄像机与先进的图像处理技术,已经能够实现基本的眼动追踪功能。然而,鉴于普通相机在捕获眼部图像时的精度局限性,对于VR/AR等要求更高精准度的应用领域,主流解决方案转向了采用集成于VR眼镜或头戴式显示设备中的红外摄像机,并辅以红外光照明器来强化眼部特征识别,进而达成更为精确的眼动追踪效果。此技术的一大优势在于,由于红外线属于非可见光谱范围,因此能够有效避免环境光线的干扰,无论是白天还是夜晚均能稳定运行,同时确保用户的视觉体验不受影响。此外,EyeTrackVR等开源眼动追踪工具,也成为了推动眼动追踪技术普及的重要力量。
基于红外摄像机的检测大多基于以下两种原理:
巩膜-虹膜边缘法(图 29.21)通过测量巩膜和虹膜边界处反射的红外光来追踪眼球运动。红外光的反射强度会随眼睛转动而变化:当眼球向一侧移动时,虹膜在该方向上的面积增大,相应侧的红外反射减少,而另一侧的反射增加。通过计算这一差分信号,可以无接触地测量眼动。该方法在水平方向的精度较高,但垂直方向的精度较低,易受环境光干扰,并且对头部位置变化较为敏感,误差较大。
瞳孔-角膜反射追踪法(图 29.22)利用红外光照射眼睛,在角膜表面形成稳定的反射光斑(Purkinje 反射点)。在光源和头部相对位置不变的情况下,角膜反射点的位置不会改变,因此可以作为眼球和摄像机的相对位置基准。通过测量瞳孔中心位置与角膜反射点的相对位移,可以计算视线向量坐标。进一步结合校准程序,建立视线向量与屏幕注视点之间的映射关系,实现对用户注视位置的实时跟踪。这种方法具有较高的精度,广泛应用于VR/AR设备、驾驶员监测和人机交互系统。
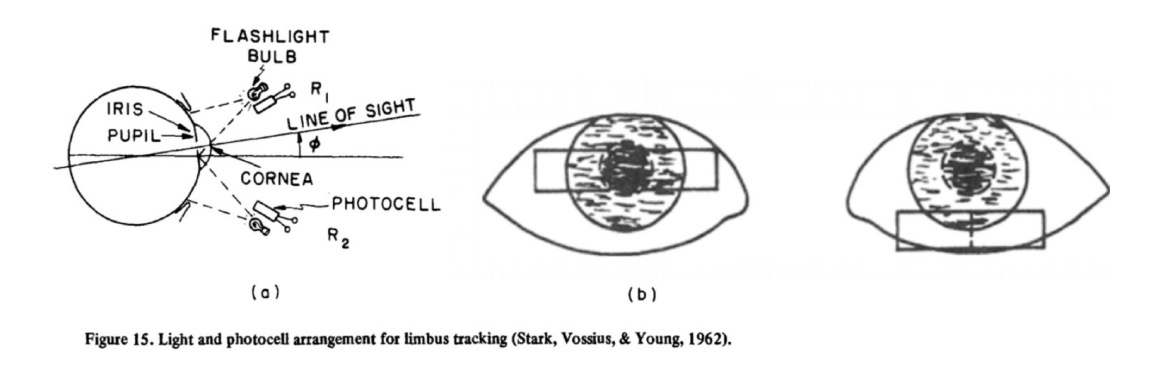
图 29.21 巩膜-虹膜边缘法。#
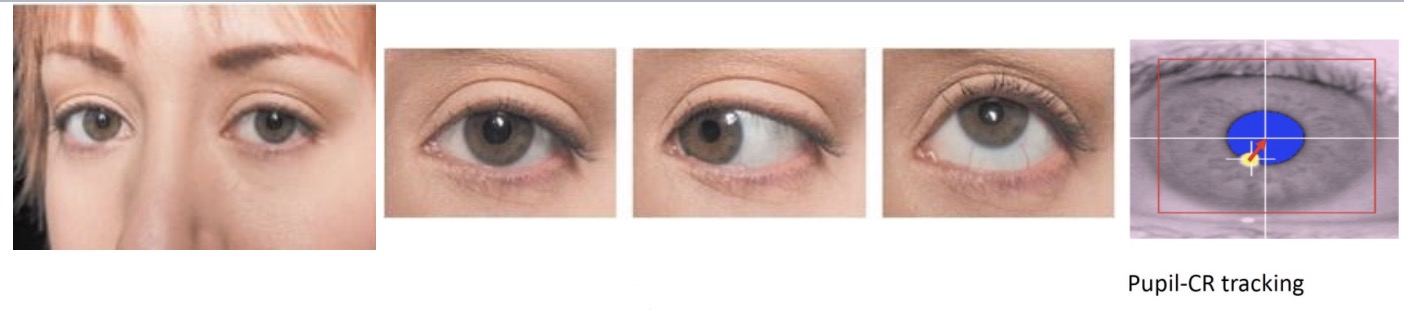
图 29.22 瞳孔-角膜反射追踪法#
利用眼动追踪进行交互面临着“米达斯接触”问题(Midas Touch Problem):在眼动交互系统中,如果光标始终随着用户视线移动,可能会引起误操作或用户的厌烦,因为用户可能只是随意浏览,而不希望每次转移视线都触发计算机命令。在理想情况下,系统应在用户有意控制时响应视线输入,而在其他情况下忽略其视线移动。为此,眼动追踪也可以结合其他交互方式(如键盘、语音输入)来触发操作,以避免误触问题。 一款理想的眼动追踪系统应满足以下要求:
不妨碍视野,确保用户能够自然观察环境;
无接触、低干扰,不会影响用户的日常活动;
高精度,能够精确检测并响应细微的视线移动;
动态范围大,从 1 弧分(1/60°)到 45° 之间均可追踪;
高速响应,能够实时捕捉眼动变化;
与身体和头部运动数据结合,提供更稳定的追踪效果;
定位校正简单,用户无需频繁进行复杂的校准过程;
29.1.3.3. 语音识别#
语音识别通过将人类的语音自动转换成文本进而识别交互指令。语音交互操作便捷、学习成本低,无需接触,还适用于远距离交互和无屏幕设备交互,被广泛用于各类应用场景。智能语音助手如Siri、Google Assistant等,能够通过语音命令控制设备并提供服务;语音转写技术可以将会议录音或采访内容自动转为文本,便于记录和分析;实时语音翻译功能则通过语音识别与机器翻译技术相结合,实现多语言之间的即时翻译。此外,语音控制技术在智能家居、汽车导航等领域也得到广泛应用,用户可以通过语音控制家电、导航系统等设备。
目前主流的语音识别技术是基于统计模式识别的理论开发的。 它所要解决的基本数学问题是:给定输入信号或从每帧语音中识别出来的升学特征序列 \(o=\{o_1,\,o_2,\,\cdots,\,o_n\}\),符号集(字典)\(W=\{W_1,\,W_2,\,\cdots,\,W_m\}\),求解符号串 \(w=\{w_1,\,w_2,\,\cdots,\,w_n\mathop{|}\forall i,\,w_i\in W\}\),使得 \(w=\mathop{\mathrm{\arg\max}} \mathrm{P}(w|o)\),\(w\) 即为语音输入对应的字符串。利用贝叶斯公式可得 \(w=\mathop{\mathrm{\arg\max}} \mathrm{P}(o|w)\mathrm{P}(w)/\mathrm{P}(o)\)。由于给定输入信号后 \(\mathrm{P}(o)\) 是确定的,因此上述问题等价于求解:
经典的语音识别流程分为以下几个阶段:
首先,通过麦克风等设备采集用户的声音信号,并对信号进行预处理,如噪声去除和特征提取;
然后,使用声学模型(如隐马尔可夫模型)对音频信号进行分析,识别出其中的语音单元;
根据发音词典所所建立的语音单元与语言单元间的映射,找到音素对应的单词;
最后语言模型根据上下文进行优化,确保识别结果符合语言习惯,另外可能还会使用自然语言处理(NLP)技术修正错误,恢复标点符号,使识别结果更自然。
语音识别技术的最重大突破之一是隐马尔可夫模型的应用,因为它通过建模语音信号的状态转移过程来识别音素,提供了一种严谨、高效、可扩展的方法来处理语音信号序列。深度神经网络也被广泛用于语音识别中,通过卷积神经网络(CNN)和长短时记忆网络(LSTM)处理音频信号中的时序信息,并实现端到端的语音识别,这一方法较传统技术更加精准和高效。近年来,基于深度学习的端到端语音识别技术逐渐成为主流,它通过深度学习模型直接将音频信号转化为文本,省去了传统模型中的特征提取和分帧等步骤。
语音识别技术已经在实际使用中达到了较好的效果,但仍然会受到一些因素的影响,如环境噪声干扰、口音、人物音色等,汉语本身的四声特点、如何进行不同语种混杂的识别也是需要关注的问题。不过,随着深度学习、噪声消除、语境理解等技术的进步,语音识别将进一步提升其实用性,并在未来的人机交互领域发挥更加重要的作用。
29.1.3.4. 多通道交互的基本特点#
使用多个感觉和效应通道:同时使用多个感知通道(如视觉、听觉、触觉等)来提升用户的交互体验,用户在交互过程中能够更全面地表达操作意图和感知系统反馈。
允许非精确的交互:与传统的单一通道交互相比,多通道交互不要求用户进行高度精确的操作。通过多种感知通道的配合,系统可以更灵活地响应用户的意图,即使操作略有偏差,也能保证交互的有效性和流畅性。
三维和直接操纵:多通道交互允许用户在三维空间中进行操作,支持更自然的直接操控,用户能够以更直观的方式与虚拟世界中的对象进行互动。
交互的双向性:输入输出通道可能产生复杂的耦合,如视线追踪的交互结果将反馈给眼睛,力传感器可以提供触觉反馈。这种双向的交互形式增强了用户的沉浸感。
交互的隐含性:具体的交互操作内容是隐含但自然直观的,符合人类日常行为,使得用户无需额外培训即可直觉地使用系统。