28.3. 交互技术的评估方法#
在设计与开发交互系统的时候,我们首先需要考虑交互系统的可用性问题。可用性,顾名思义,是反映用户在使用该交互系统的时的效率与体验的指标。可用性越高,代表用户在使用该交互系统的时的效率越高,体验越好,用户便会有更强的意愿去继续使用该交互系统。
通常来说,交互系统的可用性主要包含如下几个方面:
易学性 (learnability):易学性指的是用户学习交互系统相关功能的难度。为了实现与该系统的交互过程,用户首先需要学习交互系统的操作方式与操作规范。如果交互系统的操作方式或操作规范过于繁杂,用户便可能难以掌握交互系统。这导致用户需要频繁的通过尝试和查阅资料的方式来学习交互系统的操作方法,也间接的带来更高的交互成本,降低交互系统的可用性。
可发现性 (discoverability):可发现性指的是用户是否能够自主发现该系统是能够交互的,以及能否能够自主找到对应交互功能。在用户使用交互系统之前,用户首先发现该系统是一个可以通过交互过程获取有效信息的系统;在与交互系统的交互过程中,用户也需要自主找到自己所需的对应功能进行交互。如果用户难以发现交互系统和交互系统的功能,用户便无法主动使用交互系统和其支持的功能,转而降低交互系统的可用性。
潜在错误 (error-proneness):潜在错误指的是用户在该交互系统中期望进行错误操作的次数。潜在错误会导致交互系统返回了错误的交互结果,使得用户接受错误的信息。这增加了用户检查信息正确性的成本,也带来了较高的接受错误信息的概率,降低交互系统的可用性。潜在错误的多少与以下两个特性有关:
准确性 (accuracy):准确性指的是为了得到最终计算结果,用户期望进行的操作次数。操作次数越多,产生错误结果的机会也会越多。
可靠性 (reliability):可靠性指的是系统产生运算错误的概率。系统越不可靠,单次操作返回错误结果的概率越高。
有效性 (effectiveness):有效性指的是交互系统进行计算的效率高低。如果交互系统计算效率低下,用户便需要花费更长的时间来获取交互的结果,导致用户使用交互系统的时间成本极大地增加,降低交互系统的可用性。
满意度 (satisfaction):满意度指的是用户是愿意持续性地使用该交互系统的交互方式。交互方式是否符合人类思考习惯,交互功能是否足够强大等因素都会影响用户的满意度。满意度不足大概率能够说明该交互系统存在一定的设计问题,说明可用性不足。
28.3.1. 常用评估方法#
对交互系统的可用性进行评判是在设计与开发交互系统时的重要指标。但是,交互系统可用性包含易学性、效率、满意度、可发现性等多个用户主观评价因素,因此难以使用简单的数学计算方式计算可用性。 设计者往往会采用如下的几类方法,来评估该交互系统的可用性质:
用户模型 (User Model): 用户模型指的是对交互系统的目标用户群体的信息的建模。用户模型能够帮助交互系统的设计者了解用户群体的角色特征,需求,使用环境,目标等基本信息的分布,从而更好的设计出更加符合期望用户群体的交互系统。同时通过调查实际使用交互系统的用户分布,设计者可以分析期望用户模型与其的差异。利用该差异设计者可以分析交互系统设计的优秀和不足之处,并在之后进行针对性的改进。准确的用户模型能够极大的提升交互系统设计的可用性,而不准确的用户模型可能会对交互系统的设计目标产生误判,导致用户交互体验极大的降低。
启发式评估 (Heuristic Evaluation): 启发式评估指的是请专家会对用户界面进行评判,确保其设计符合行业中普遍认可的可用性原则。专家会根据一组基于长期的用户研究和实际经验的可用性原则,独立对交互系统进行系统。在评估时,由 Jakob Nielsen 提出的十大可用性原则是最常用的。该原则包括:保证系统状态的可见性;交互操作的一致性;为用户提供交互帮助与文档;符合用户思考习惯等内容。该方法能够在早期判断交互系统的可用性,但是判断的准确性很大程度长依赖于专家的知识储备。同时,专家观察的角度与用户也存在一定的差异,因此部分可用性问题可能无法发现。
认知性遍历 (Cognitive Walkthrough): 认知性遍历指的是让设计者执行表达任务。这个表达任务需要表达用户在使用交互系统每个步骤需要知道什么信息,之后进行什么操作来完成角色目标。这能够帮助设计者从用户的角度思考交互系统的设计。但是由于其有作为设计者对于该交互系统的先验知识,在执行表达任务的时候会附带固有的对交互系统的更为全面的了解。因此认知性遍历仍然会带有一定的设计者的认知偏差,其效果不如放声思考法。
用户测试 (User Testing): 用户测试指的是通过让实际用户在现实环境中使用交互系统,并评估其可用性。通过用户测试的方式,设计者能够获取用户在使用者的不同视角下对该交互系统的评价与建议,将上述信息整理收集后可以进行针对性的改进。用户测试更多会作为交互系统上线前的可用性测试方式,评估内容会更多关注交互系统的整体大框架。
用户问卷调查 (Questionnaire): 用户问卷调查指的是让实际用户在实际使用交互系统后填写满意度的问卷。设计者可以使用标准的、经过验证的问卷与用户进行交互,将上述信息整理收集后可以进行针对性的改进。用户问卷调查更多会作为交互系统上线后的可用性测试方式,其评估方式更多会关注交互系统的细节交互方式调整。
放声思考法 (Think-Aloud Method): 放声思考法指的是让用户说出他们在每个时刻所看到、想到、做的事情和感受。通过观察与记录用户在实际交互的时候做的事情以及感受,设计者能够以确定他们的期望,并确定交互系统的哪些方面令用户困惑,哪些方面另用户感到满意。由于用户能够实时的反应其在交互式后的真实方法,且在交互过程中不存在认知性遍历中设计者拥有的对交互系统的全面了解。因此放声思考法是上述方法中效果最好,最准确的可用性评估方法。
接下来,我们来具体的介绍几种较为常见的交互系统可用性评估方法。
28.3.2. 系统可用性量表#
如图 28.23 所示,系统可用性量表(System Usability Scale,SUS)是一种简单的包含十个问题的李克特量表(Likert Scale),可以较为全面地反映系统可用性的主观评估。李克特量表通过让被试者在一系列陈述中选择自己的态度或意见,以评估被试者对某个主题的看法或态度,通常包括五个等级,从强烈同意到强烈不同意。系统可用性量表由英国数字设备公司的约翰·布鲁克(John Brooke)于 1986 年开发,并最初作为电子办公系统可用性工程的工具。
系统可用性量表包含十个与系统使用体验相关的陈述性语句。对于每一个语句,用户可以从五个选项中选择一个,来表示该语句与用户在实际使用系统体验之中的相符程度。通过对每个语句相符程度的线性加权求和,设计者能够较为简单的获取一个对系统可用性的评价。例如,针对图 28.23 的系统可用性量表,我们可以根据陈述性语句与系统可用性的关系,将问题分为积极的 \(1,3,5,7,9\) 和消极的 \(2,4,6,8,10\) 两组。假定 \(Q_i\) 表示第 \(i\) 的问题用户的评价,则我们可以根据问题的积极性与消极性分布求和,并通过线性组合最终得到如式 (28.1) 的可用性计算方法。
由于其设计简单,用户评价时间短,且能够提供一个显式的数字评分作为可用性的估计,系统可用性量表广泛应用于用户问卷调查,用户测试等可用性评估问题上。

图 28.23 系统可用性量表实例。© Wikipedia#
28.3.3. A/B 评测#
A/B 评测(Formal A/B Studies)是简单随机对照实验其中一种。在 A/B 评测系统中,设计者需要设置对于新旧交互系统,或者是相同交互系统的不同设计方式的对照。进行测试的时候,测试者可以选择同时向用户展示两者,也可以向用户随机的展示两种交互系统的其中一种。通过上述测试,设计者能够更好的了解用户对于两种不同交互系统的满意度,参与度,使用倾向等主观信息。同时,设计者能够统计用户在进行对比试验时候的使用交互系统交互次数,交互时间,潜在错误数量等客观信息。将上述主观信息和客观信息进行统计后,设计者便能够通过数据的对比对两种交互方式的可用性优劣程度,并针对性地给出修改意见。一个评估实例如图 28.24 所示。也可以将 A/B 评测进一步的拓展为多个交互系统的对比实验,来比对多种设计之间的差距。
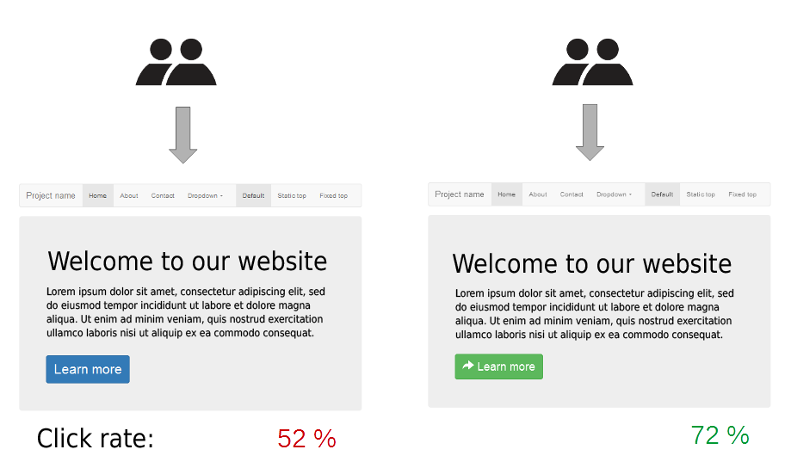
图 28.24 A/B 评测数据展示实例。随机为访问者提供两个版本的网站,这两个版本只在一个按钮元素的设计上有所不同,通过比较用户的点击率可以衡量两种设计的相对效果。© Wikipedia#
A/B 评测常常用于学术论文等需要较严谨的数据比较的场合。由于 A/B 评测的数据来源于对受试者的随机采样,因此在进行数据展示的时候通常需要添加置信区间,如图 28.25 所示。
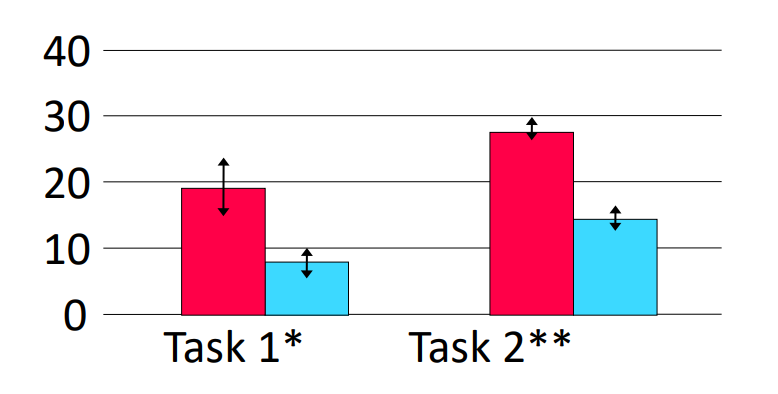
图 28.25 带有置信区间的 A/B 评测数据展示实例。#
28.3.4. 专家反馈 (Expert Evaluations)#
专家反馈是指让专家检查交互系统的可用性。最常用的专家反馈评估就是启发式评估法,也就是根据符合行业中普遍认可的可用性原则评测交互系统。由雅各布·尼尔森(Jakob Nielsen)提出的十大可用性原则 [Nie05] 是最常用的。该原则包括:
可见性(Visibility of system status): 系统应始终让用户了解当前状态,通过及时的反馈让用户知道操作是否成功,以及系统正在做什么。
环境贴切(Match between system and the real world): 界面设计应符合用户的认知习惯,使用用户熟悉的语言和符号,使操作流程自然流畅。
用户可控(User control and freedom): 用户应该能够自由地撤销或重做操作,避免陷入困境。
一致性(Consistency and standards): 保持界面元素、交互方式的一致性,避免让用户产生困惑。
防错(Error prevention): 设计上应尽量避免用户出错,例如,通过预设合理的默认值、提供确认机制等。
识别胜过记忆(Recognition rather than recall): 用户界面应尽量减少用户的记忆负担,通过可见的选项、指示器等方式,让用户能轻松识别和选择。
灵活高效(Flexibility and efficiency of use): 为不同经验水平的用户提供不同的操作方式,例如,提供快捷键或加速器。
美观简约(Aesthetic and minimalist design): 避免不必要的元素和信息堆砌,保持界面简洁美观,突出重点。
容错(Help users recognize, diagnose and recover from errors): 当用户出错时,系统应提供清晰的错误提示和恢复方法。
人性化帮助(Help and documentation): 在需要时提供简洁易懂的帮助文档,帮助用户解决问题。
评测时候专家会详细检查整个交互系统的交互页面,将观察到的问题分类归纳到可用性原则中,并分别给出对应的修改意见。再给出修改意见后,设计者进行整理并进行针对性的修改。

图 28.26 Jakob Nielsen 提出的十大可用性原则。#
针对基于不同平台的设计系统,专家往往也会给出其对应的可用性原则。例如苹果针对 IOS/MAC OS 平台提出了该平台上的可用性原则,其中包括了限制屏幕上的控件数量,无缝使用在横屏竖屏等不同场景下的展示风格,在获得许可的情况下使用免密支付等原则。同时,苹果也向设计者展示了交互系统运行的平台信息。通过上述原则,苹果能够帮助设计者在设计基于 IOS/MAC OS 平台上的交互系统的时候,能够更好的服务于用户的交互需求。

图 28.27 苹果为开发者提供的可用性原则展示页。#