20.1. 动作捕捉#
当我们有一个虚拟角色和它的骨骼框架以后,一个很直接的让其动起来的方法,就是手动指定每个关节的弯曲程度。整个过程就像操控一个玩具小人一样,我们将其摆成我们想要的姿势。然而这样只能得到一个静态的姿势,如何产生整个的运动呢?如果能结合之前讲过的插值内容,可以发现做法也是很简单的:我们把几个关键的姿势摆出来,通过插值产生姿势之间的切换,如图 20.1。

然而这样的方法只适用于大范围的,非精细的运动。由插值产生的动作往往较为平滑,缺少细节和风格。在一些快速的多变的运动中,我们需要非常多的关键帧才能确保动画的质量,而这会导致我们的工作量大幅度上升。
这时我们就要依赖另一个产生动作数据的重要方法:动作捕捉(motion capture),一般读为“Mocap”。动作捕捉是通过设备记录人和物体运动的方法。就角色来说,我们需要一些专业的动捕演员,让其穿戴特定的设备进行表演。在每一时刻,演员的肢体运动甚至面部表情会都会被设备记录下来,转化成骨骼的旋转数据,记录完毕后将其交给后续的处理流程。

相比于插值动画,动捕数据由于是对演员的动作进行了密集的捕捉,可以较为简单地获得非常风格化和流程的动作。动作捕捉在如今有非常多的应用,下面列出了几个主要的方面:
休闲娱乐:如游戏、影视、虚拟偶像、元宇宙。
体育运动:如运专业体育训练、演出动作的优化。
医疗:用于帮助医生诊断、治疗一些与运动相关的疾病,以及受伤复建等。
机器人:例如对无人机、机械臂的跟踪和定位。
在进行动作捕捉时,我们需要一些设备来完成动作的提取和转化,根据不同的原理,我们可以将设备进行分类,我们将在下面的章节对这些设备进行简单的介绍。
20.1.1. 外骨骼#
基于外骨骼(exoskeleton)的动捕设备是一种早期较为常用的动捕设备,如图 20.3 所示。外骨骼设备的原理十分简单,由于动捕演员穿戴了一套外骨骼,演员的肢体动作会带动外骨骼运动,通过测量外骨骼各关节的角度来近似人体上对应关节的角度;在拥有各关节角度之后,结合外骨骼设备的内参(如每个部件的长度等),我们就可以利用 §19.2.1 中的方法还原人体的动作了。

图 20.3 基于外骨骼的动捕设备#
基于外骨骼的动捕技术最大的问题在于穿戴的设备特别妨碍动捕演员做动作,当我们需要做一些比较难或者比较危险的动作时(比如躺在地上)穿着外骨骼就很难实现。但另一方面,外骨骼技术非常适用于手部动作的采集,因为手相对身体比较小,采用外骨骼技术能够获得更加准确的数据。
20.1.2. 惯性传感器#
基于惯性传感器的动捕技术(如图 20.4)主要依赖于惯性测量单元(inertial measurement unit,IMU),它一般是一个六轴传感器,包括 \(3\) 自由度的加速度计(accelerometers)和 \(3\) 自由度的角速度计(gyroscope)。通过这些传感器的信息,我们可以得到人体各部位的相对运动,进而使用逆向运动学(§19.2.3)或者优化的方法来求解每个关节的旋转。
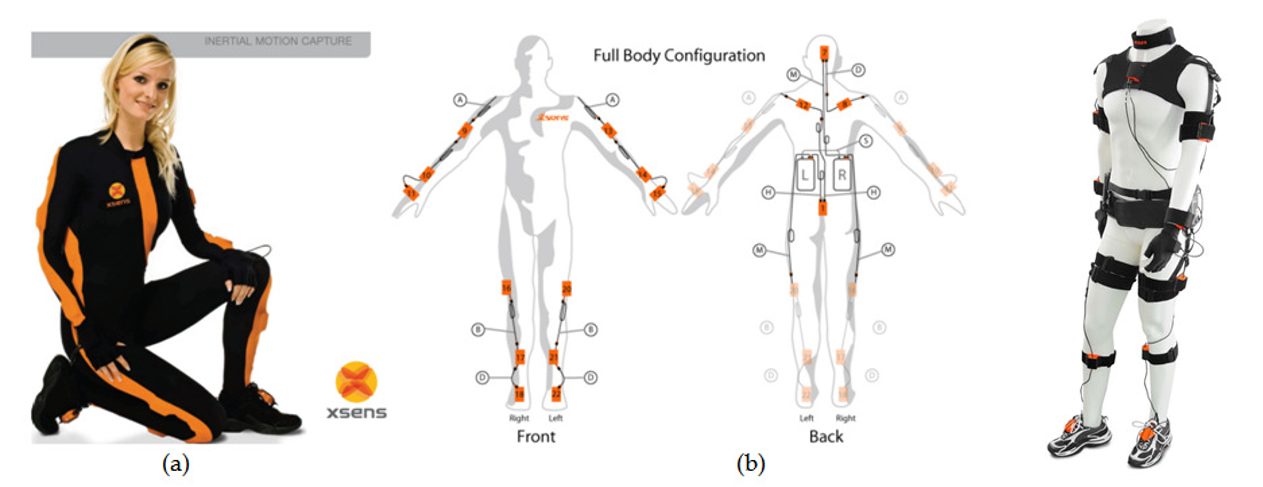
图 20.4 基于惯性传感器的动捕技术#
基于惯性传感器的动捕技术存在的一个不可避免的问题就是传感器的漂移。由于惯性传感器测量的是加速度或者速度,为了得到位置,需要对加速度或速度进行积分,而随着时间的推移,这个积分的误差会累积,导致得到的位置关系越来越不准确。在实践中,常常会因此看到人物会飘起来或者陷进地面。我们往往会借助其他技术来减少漂移带来的影响,比如一些启发性的辅助措施,例如我们可以借助“人的脚总是接触地面”这个先验知识来对整个人体的位姿加一个修正项;另外一方面我们也可以使用更精确的或者添加更多的传感器来减小积分时产生的误差,例如可以借助重力传感器来避免在竖直方向产生过大的漂移,类似还可以借助磁场传感器、光流传感器等。
20.1.3. 光学动捕#
 (a) 标记点
(a) 标记点
 (b) 相机组
(b) 相机组
图 20.5 光学动捕#
光学动捕(optical mocap)是目前最为流形的一种动捕技术,其主要原理是通过相机来进行三维定位。动捕演员需要穿戴一些反光或发光的标记点(如图 20.5(a)),此外场景中会放置多个(一般是 \(6\) 到 \(8\) 个,如图 20.5(b))摄像机,每个相机都能够拍摄到这些标记点,通过多个视角的标记点位置来重建每个标记点的三维坐标。于是,我们只需要在动捕演员身体上的每个关节处都放置若干个标记点,通过这些点的三维坐标就可以反推出每个关节的位置和朝向。
20.1.3.1. 多视角重建#
这里介绍一种利用两个相机重建标记点三维位置的方法。如图 20.6 所示,我们已知两个相机的焦距、位置、朝向信息,就可以在为每个相机作一个平面表示相机拍摄到的图片所在的屏幕,一个标记点会在两个屏幕上分别投射出一个点,我们从两个相机的焦点出发向各自屏幕上对应点引出一条射线,那么两条射线应当能够相交,这个交点就是还原出的三维位置。
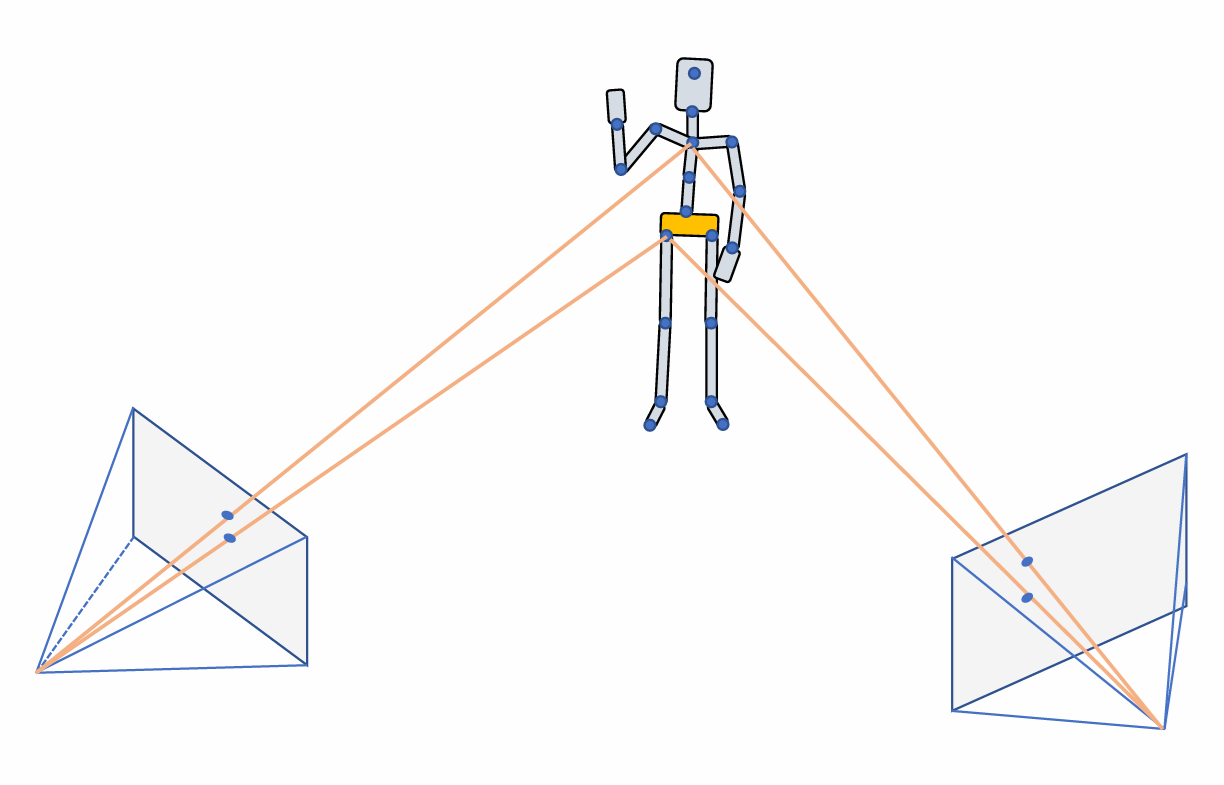
图 20.6 双视角还原标记点位置#
这个方法虽然简单,但并不常用,因为实际情况中两个相机会带来较大的测量误差。一般来说我们至少需要 \(3\) 个相机来定位一个点,且相机越多误差越低,尤其是当场景中出现遮挡关系时更加需要多个相机来准确地重建。
20.1.3.2. 标记点的丢失#
光学动捕的一个常见问题在于标记点在动作过程中很可能会丢失,比如当动捕演员趴在地上时,没有任何摄像机能够看到胸口的标记点;此外,在进行复杂动作的过程中可能会使标记点错位。这些问题对光学动捕是十分不利的,所以人们往往需要耗费大量精力为采集到的数据进行补点操作,补齐丢失的标记点或是纠正对应错误的标记点(例如有些手上的标记点可能会被算法误认为是腿上的标记点)。这种后处理工作繁琐且昂贵,在业界这种工作往往是按照动捕序列的时长以秒为单位计费的。近期也有一些研究借助机器学习来简化这个补点的过程,感兴趣的读者可以深入调研。
20.1.3.3. 无标记点的光学动捕#
由于标记点占据一定的体积,动捕演员携带标记点做动作往往会受到影响,尤其是在采集动物的动作数据时。针对这个问题,目前最常见的解决方案是采用基于多视角相机的无标记点的动捕技术 (如图 20.7)。其原理与普通的光学动捕技术类似,已知多个相机的内参和位姿,通过识别每个相机拍摄出图像中的关节等特征来重建人体姿态。但这类方法的准确性会受光线等因素影响。

图 20.7 无标记点的光学动捕#
20.1.3.3.1. 基于深度相机的无标记点光学动捕#
深度摄像机拍摄出来的图片中每个像素点除了颜色信息外还会携带深度信息,通过额外的深度信息我们可以重建出人物的表面网格,进而重建出人物的姿态。图 20.8 展示了一个深度相机,图 20.9 和图 20.10 分别展示了两种使用深度相机重建出的人物动画。当然,在不同身体部位之间出现遮挡时,深度相机动捕就会遇到问题;另外,单视角深度相机也难以区分拍摄到的是身体的(前、后、左、右)哪一侧。
总体来说,无标记点的光学动捕精确度不如传统的光学动捕技术高,当然这也说明这方面技术还有很大的进步空间,它们也是近期研究的热点。

图 20.8 一个深度相机#

图 20.9 使用深度相机重建的骨架#

图 20.10 使用深度相机重建的人物动作#
20.1.4. 其他运动估计方法#
另外还有一些运动估计(motion estimation)的方法,它们可以借助低成本的设备还原出一个较为合理的动作,但由于这些方法的输入往往是不够的,不能准确地还原出人体动作,所以被称为运动估计而非动作捕捉。
20.1.4.1. 基于单视角视频的运动估计#
 二维姿态估计
二维姿态估计
 基于视频的三维姿态估计
基于视频的三维姿态估计
图图 20.11 展示了两个基于单视角视频运动估计的研究工作。由于单视角相机看到的是三维动作到二维的投影,输入具有一定的歧义,我们只能结合大量的训练数据来估计一个最大可能性的动作。
20.1.4.2. 使用少量传感器进行运动估计#
 (a) 借助稀疏的惯性测量单元进行运动估计
(a) 借助稀疏的惯性测量单元进行运动估计
 (b) 虚拟现实中的运动估计
(b) 虚拟现实中的运动估计
图 20.12 使用少量传感器进行的运动估计#
这类方法往往只需要借助很少量的(\(5\) 到 \(6\) 个)标记点或传感器进行运动估计(如图 20.12(a)),这类方法可以借助逆向运动学技术还原出人物动作。在虚拟现实场景中,我们甚至只有 \(3\) 个已知的标记点(虚拟现实头盔、两个手柄,如图 20.12(b),有时甚至只有头盔这一个标记点的信息)。对于这种信息极度缺失的病态问题,目前的技术能够达到的效果也很有限,但这同样意味着我们还有很大的研究空间。