24.1. 可视化概述#
24.1.1. 什么是可视化#
可视化是将不可见或难以直接显示的数据、信息或概念以图形、图表、图像或其他符合人类感知的视觉形式呈现的过程。 从分析全球股市波动,到研究全球气候和洋流变化,从社会经济发展数据、城市的交通移动数据到个人的健康与运动数据,可视化在各个领域中都展现了重要的意义和价值。 它既可以通过将抽象数据转化为直观的视觉叙述,更加生动地讲述故事或传达信息,也可以帮助科学家、决策者和公众更深入地理解全球气候变化、病毒结构、社会经济数据等复杂信息,发现异常情况、识别趋势和模式,并做出更加明智的决策。
通过将人纳入到数据分析流程中,很多可视化应用还支持用户进行数据科学探索、数据分析、信息传达和决策支持等任务,以此克服自动化算法在某些复杂分析和决策过程中的局限。 这种人机互动的方式不仅促进了信息的共享和合作,还加强了数据分析的深度和广度,使非专业人士也能轻松理解并应用复杂数据。
从宏观的角度看,可视化的功能可以总结为以下两点:
1. 信息表达和传播
地球演化历史可视化
图 24.2 出自2013年胡安·大卫·马丁内斯(Juan David Martinez)及其团队的设计,将地球近 46 亿年的进化过程浓缩成这样一张五颜六色的螺旋图。 这张图以螺旋形状展开,以螺旋一端表示地球形成之初,螺旋向外扩展代表时间的流逝。 螺旋上不同颜色的每一段代表了特定的地质时期,描绘了在这些时期内地球地质构造的变化以及不同生物的演化过程。
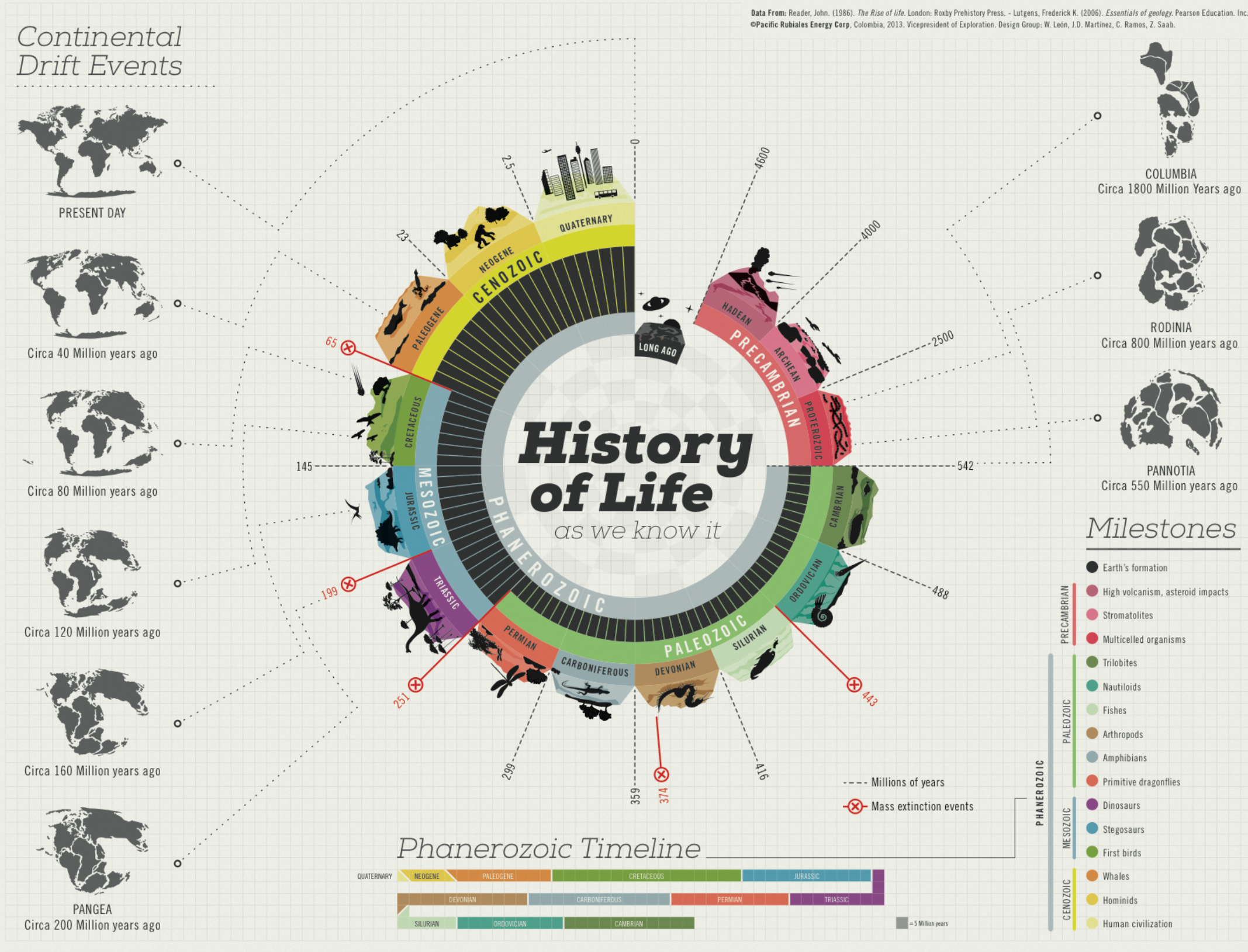
图 24.2 地球演化历史图。 © https://www.behance.net/gallery/10901127/History-of-Life#
2020 美国大选可视化
2020 年美国总统选举,在主要竞选人共和党的唐纳德·特朗普(Donald Trump)和民主党乔·拜登(Joe Biden)之间展开。 选举采用的是选举人团制度,选举人团由 538 名选举人组成,这个数字等于美国国会议员的总数(435 名众议员和 100 名参议员)加上华盛顿特区的 3 名选举人。 各州通常采用“赢者通吃”制度,即在该州赢得普选票数最多的候选人将获得该州所有的选举人票。 为了赢得选举,候选人需要至少获得超过半数,即 270 张选举人票。 因此一些关键的摇摆州如宾夕法尼亚州和密歇根州的结果对总体选举影响极大。 图 24.3 和图 24.4 分别展示了两种不同的竞选结果可视化方法。
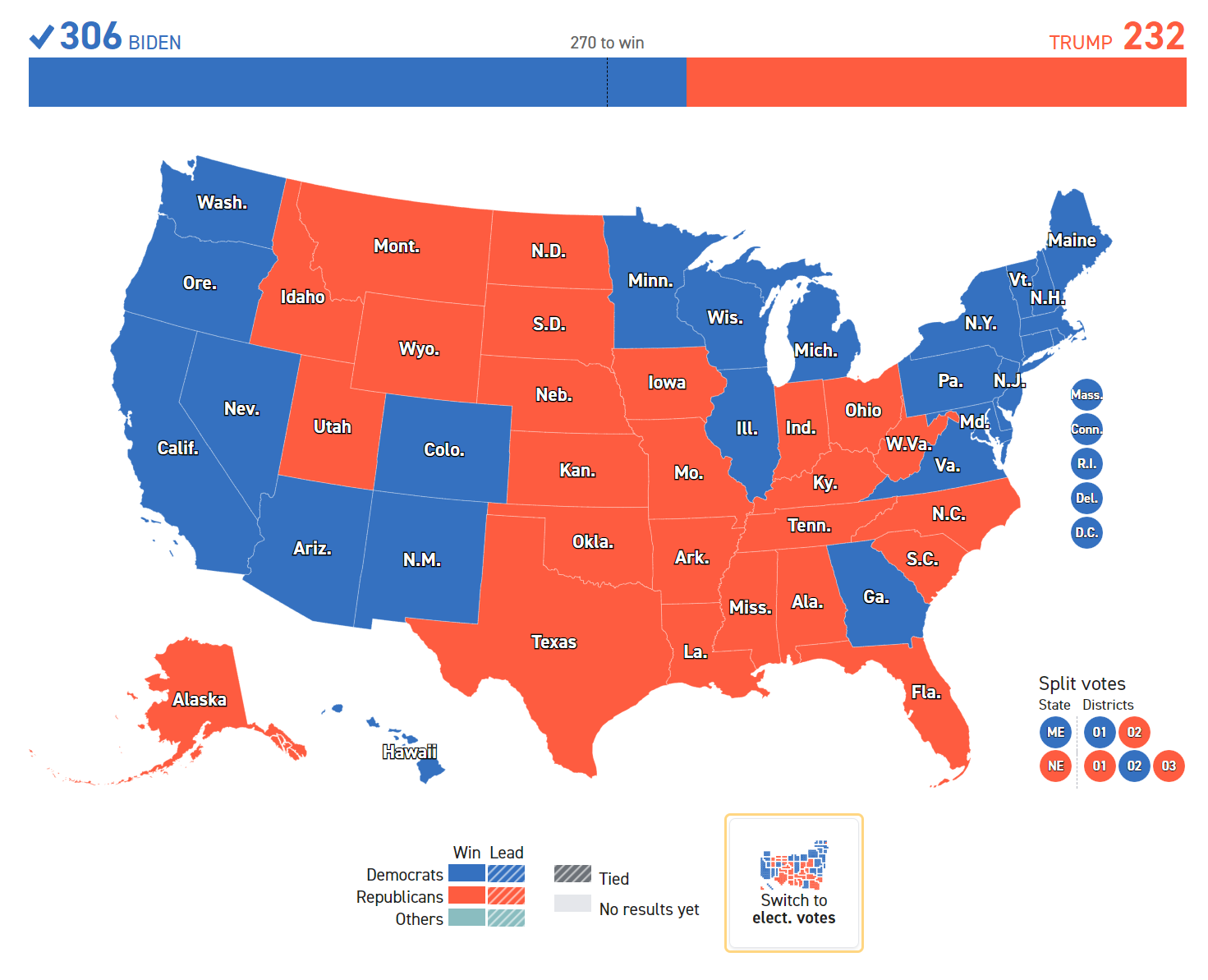
图 24.3 原始地图直接映射,观感上与实际结果不一致。 © https://www.politico.com/2020-election/results/president/#
图 24.3 展示了在原始地图上进行颜色编码的结果。 每个州票数占比和实际面积并不匹配,这会导致染色面积与得票情况不一致,从而带来困扰。
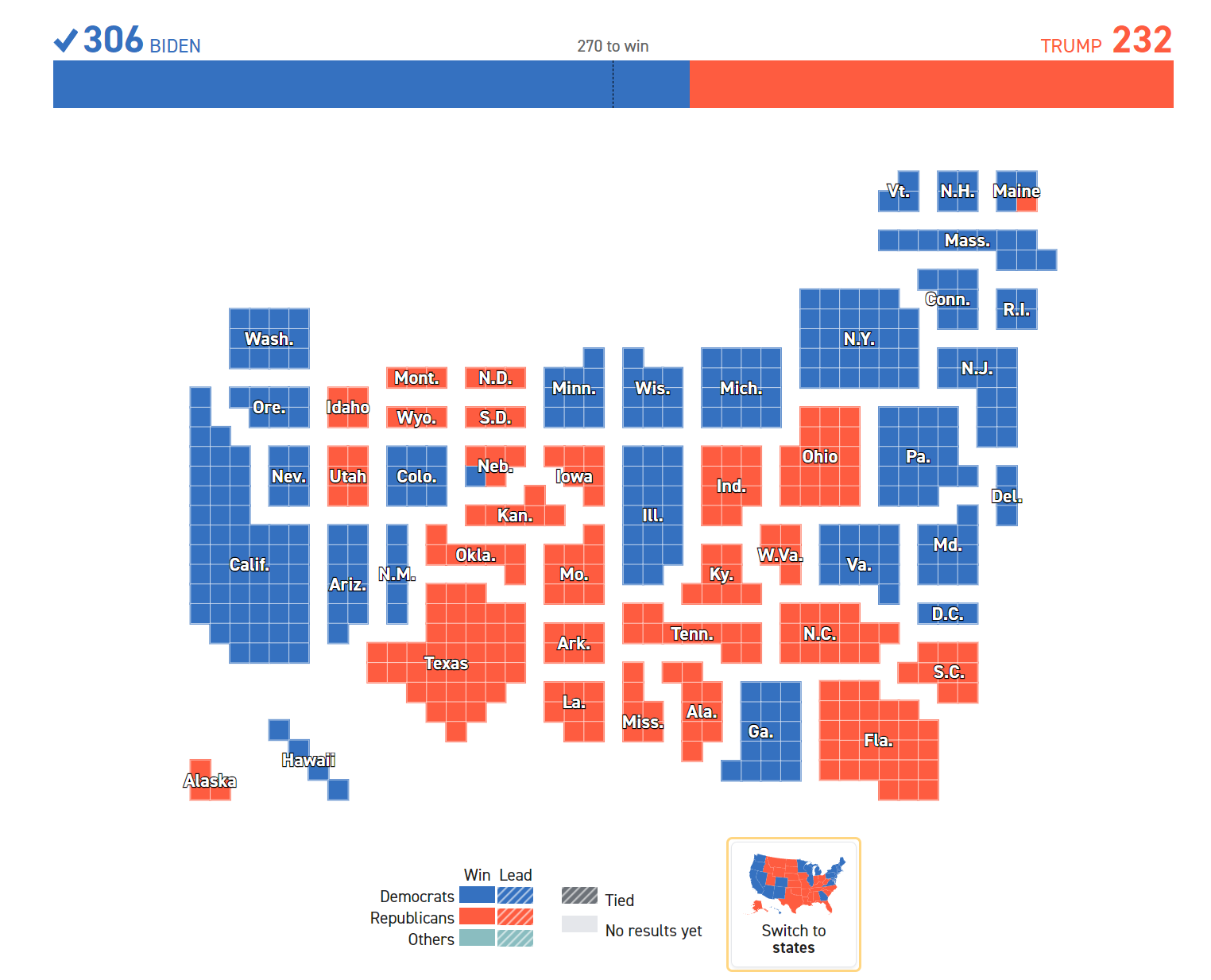
图 24.4 根据选票数量调整各州面积,观感上与投票数一致。#
因此在实际中,需要选用变形地图,如图图 24.4 所示,在部分保留各个州相对地理位置的情况下,根据选票数量调整各州面积,使得面积与票数一致,避免产生误解。
2. 信息分析与推理
拿破仑征俄图
1869 年,法国工程师查尔斯·约瑟夫·米纳德(Charles Joseph Minard)绘制了1812年拿破仑征俄图(Map of Napolean’s Russian Campaign of 1812),如图 24.5,描述了拿破仑在 1812 到 1813 年进攻俄国时所遭受的灾难性损失。此图将法军东征俄国的过程,精确而巧妙地通过数据可视化的方式展现出来,让人直观感受到拿破仑的 40 万大军,如何在长途跋涉和严寒之中逐步溃散。

图 24.5 拿破仑征俄图。© Wikipedia#
线条宽度的变化代表拿破仑的军队人数变化,黄色为进军路线,黑色为撤退路线,文字标明了行军途经的特定地点、河流以及具体人数。底部温度折线从右到左反映了撤退途中的温度变化。 通过这张图,用户能清晰读出从立陶宛到莫斯科,拿破仑军队位移的经纬度、对应的时间以及温度与军队规模等信息。 可以看到,出征时军队人数 42.2 万人,到达莫斯科时还有 10 余万人,而活着返回法国的只有 1 万余人, 观察黄黑两线交汇处,可以发现活下来的士兵大都中途走岔路返回,前进的大部分都牺牲了。 结合温度变化、河流位置、军队人数,可以看到低温和渡河是导致士兵牺牲的两大因素。
伦敦霍乱地图
十九世纪中叶,霍乱在伦敦几度流行,四万多人死于瘟疫。当时的医学界普遍认为瘟疫是靠笼罩在伦敦上空的“瘴气”传播的,而英国医生约翰·斯诺(John Snow)却认为霍乱是通过水源传播。为了证明这一点,在伦敦爆发霍乱的 1854 年,他冒着生命危险,走进病情高发的街区,挨家挨户地调查了整片街区的居民死亡情况,并绘制了一张死亡地图。
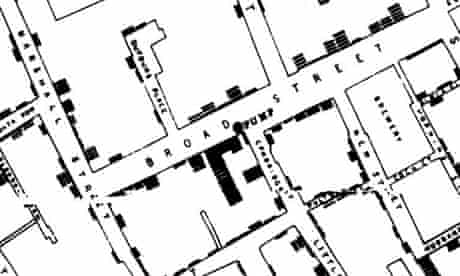
图 24.6 医生约翰·斯诺在伦敦地图上标注死者住过的地点(局部图)。© From www.theguardian.com#
如图 24.6 所示,约翰·斯诺使用点分布图(Dot Distribution Map)在地图上标出了所有死者曾经居住过的确切地点,于是他可以直观地在图上看到疾病爆发的密度和分布。当约翰走访过发病的一整个街区之后,他从图上发现了异常——有一幢房屋的死亡人数远高于其他,而这幢房子紧挨着一个生活水源。经过调查,这个水泵连通河水,那里也是生活污水的排放场所。饮用水被污染了。
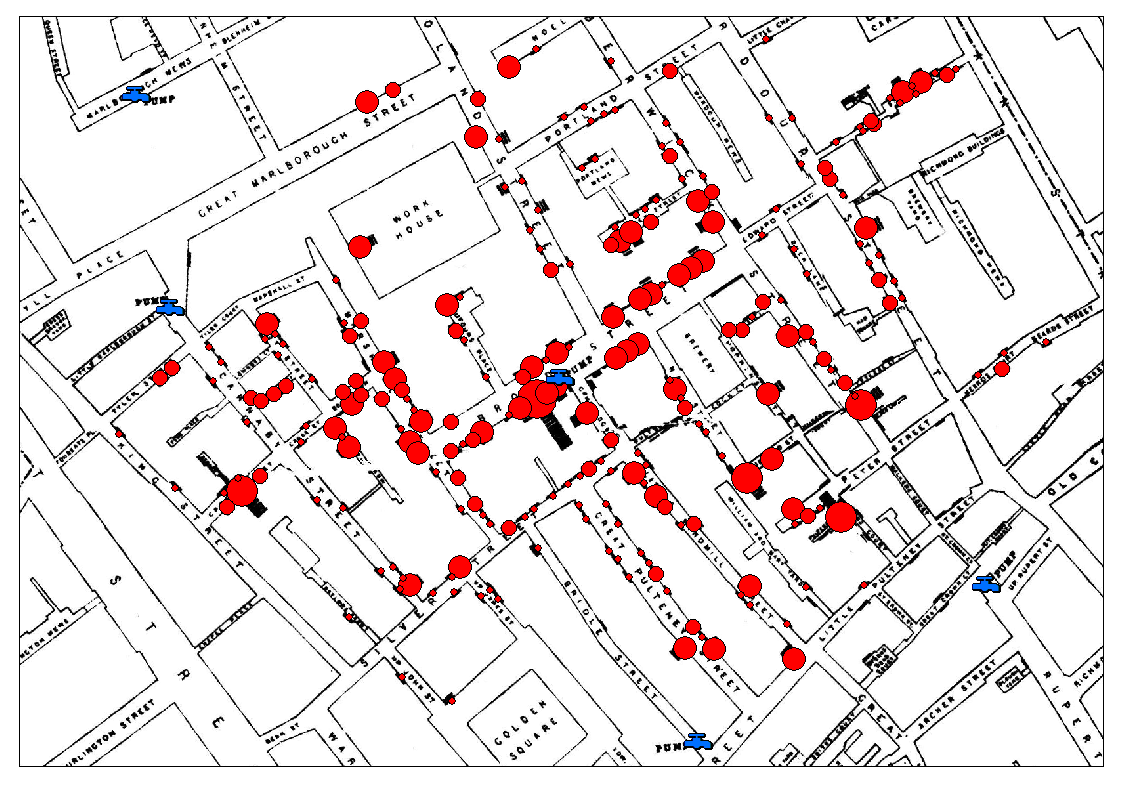
图 24.7 为了纪念,有人根据约翰·斯诺的数据,重新标注了疫情区域。 © From www.r-bloggers.com#
这张地图配合约翰调研的数据,为证明霍乱是经由受污染的水源传播提供了足够的证据。于是受污染的水源被拆掉把手,人们无法再从这里取水。不久后,整个街区的疾病流行得到了遏制。为了纪念,有人根据约翰·斯诺的数据,重新标注了疫情区域,见图 24.7。约翰·斯诺的研究在公共卫生与健康地理学中有重大意义,并被视为流行病学的发端。而死亡地图对人类做出的贡献远远超出了医学范畴。这种方法后来被广泛应用于疾病传播、犯罪、地理分析、建筑学等诸多领域的研究,甚至衍生了一门专门绘制信息地图的学科:GIS(Geographic Information System)。
南丁格尔玫瑰图
南丁格尔玫瑰图诞生于 19 世纪的克里米亚战争时期,该图表由一位名叫弗洛伦斯·南丁格尔(Florence Nightingale)的英国护士长汇总数据并绘制完成。 这张图表不仅清楚地显示了士兵死亡的原因和时间分布,还揭示出医疗条件的不足和卫生环境的恶劣。 南丁格尔玫瑰图因此成为了统计图表的先驱之一,被广泛地运用于各个领域。
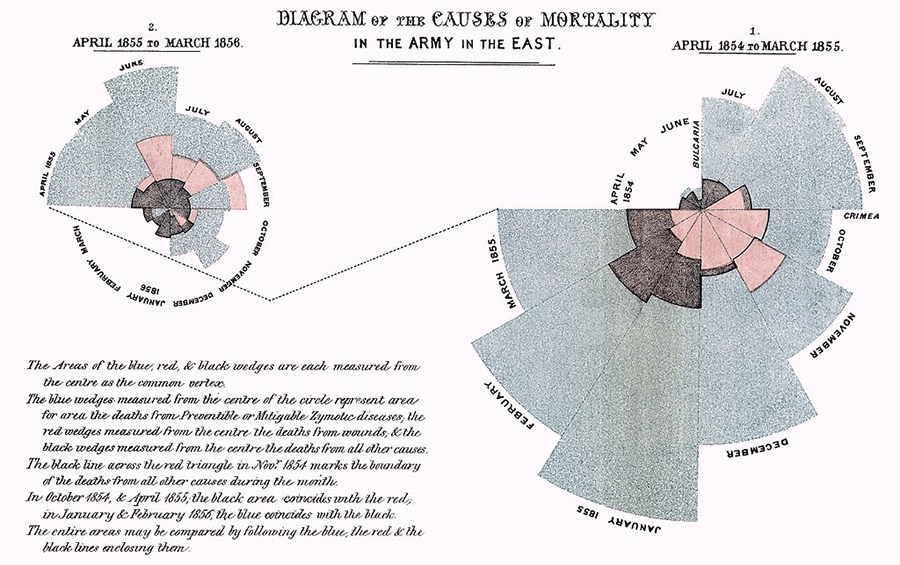
图 24.8 南丁格尔玫瑰图;蓝色表示死于可预防疾病的士兵人数,红色表示死于枪伤只的人数,黑色表示死于其他意外的人数。© Wikipedia: File: Nightingale-mortality.jpg#
图 24.8 展示了 1854 年 4 月到 1855 年 3 月这一年间士兵的死亡情况。 图中又分为两张小图左图表示 1855 年 4 月到 1856 年 3 月的死亡人数,右图表示 1854 年 4 月到 1855 年 3 月的死亡人数。 对比两张图,可清楚地看到这两年军队死亡人数的变化。
从图中可看出,这一年时间里,士兵的死亡主要不是因为战斗中的枪械伤害(红色部分),而是由于可预防的疾病(蓝色部分)。 特别是冬天的时候 (1854 年 11 月 - 1855 年 2 月),死于可预防疾病的士兵人数大幅增加。 由此可知,导致士兵大量死亡的主要原因并非是战斗本身,而是战后有效医疗护理的缺乏。 南丁格尔的这一发现不仅推动了军队医疗卫生的改善,也推动了公共卫生和医疗系统的整体改进,挽救了更多可能死于可预防疾病的士兵,对社会有着现实意义和重要价值。
24.1.2. 可视化发展历史#
可视化不仅是一种强大的工具,用于数据分析和决策制定,还是一种有效的传达和理解信息的方式。 可视化的思想在各种领域中都具有广泛的应用,有助于提高工作效率、推动创新和改进决策质量。
因此,尽管可视化作为一门独立的学科,起源于上世纪 80 年代中后期,但是可视化思想的应用却可以追溯到远古时代,例如公元前的中国就已经出现了早期的地图绘制。 在 17、18 世纪,随着测量和制图技术的进步,以及统计学的兴起,可视化迎来了第一个高峰期。那个时期涌现出一批著名的可视化作品,如 1786 年威廉·普萊菲(William Playfair)发明的条形图和饼图,1869 年查尔斯·约瑟夫·米纳德创作的拿破仑远征图。
20 世纪以后,随着计算机特别是图形显示、人机交互技术的发展,可视化进入了一个崭新的阶段。 1987 年,ACM SIGGRAPH 会议上正式提出”可视化(Visualization)”的概念。 此后,以 IEEE Visualization、EuroVis 等为代表的可视化会议相继出现,一大批可视化理论、工具、系统被研发出来,极大地推动了可视化的发展和应用。 进入 21 世纪,可视化与其他学科的交叉融合进一步加深,可视分析、可视化数据挖掘等新的研究方向不断涌现,有力支撑了大数据时代数据密集型科学研究范式的转变。